redis那些事
概述
工作的过程中有使用过redis作为热点数据的缓存,刚接触的时候还热火朝天的学了一把基本的数据类型和操作,不过并没有深入的 了解过这个东西,刚好趁闲下来的时间好好地学习一下。
详解
安装
为了方便初始化环境,采用了一种比较方便的安装方式docker安装:
1 | docker pull redis |
上帝视角
redis对外呈现的数据结构是包括string、list、hash、set、zset,不过这些种类的对象都源自于同一个结构体:redisObject,对应结构体的
定义如下所示:
1 | typedef struct redisObject { |
- type:记录了对象对外呈现的类型,分别是string、hash、list、set、zset
- encoding:用于记录该类型的对象底层采用的数据结构
- lru:记录对象最后一次被访问的时间
- refcount:表示当前对象引用计数的大小,当值为0的时候将会被回收
- ptr:指向实际数据的指针
redisObject的存在更多的像是一个门面,可以提供一些通用的函数,并没有特殊的含义或者目的
基本数据结构
redis是key-value类型的数据库,redis的key是string,对应的value则由以下几种基本数据类型组成:
- string:string的底层实现方式redisObject中的encoding包括了int、raw、embstr,其中每种具体的实现都是针对内存空间的占用和
内存分配成本的管控,具体如下:
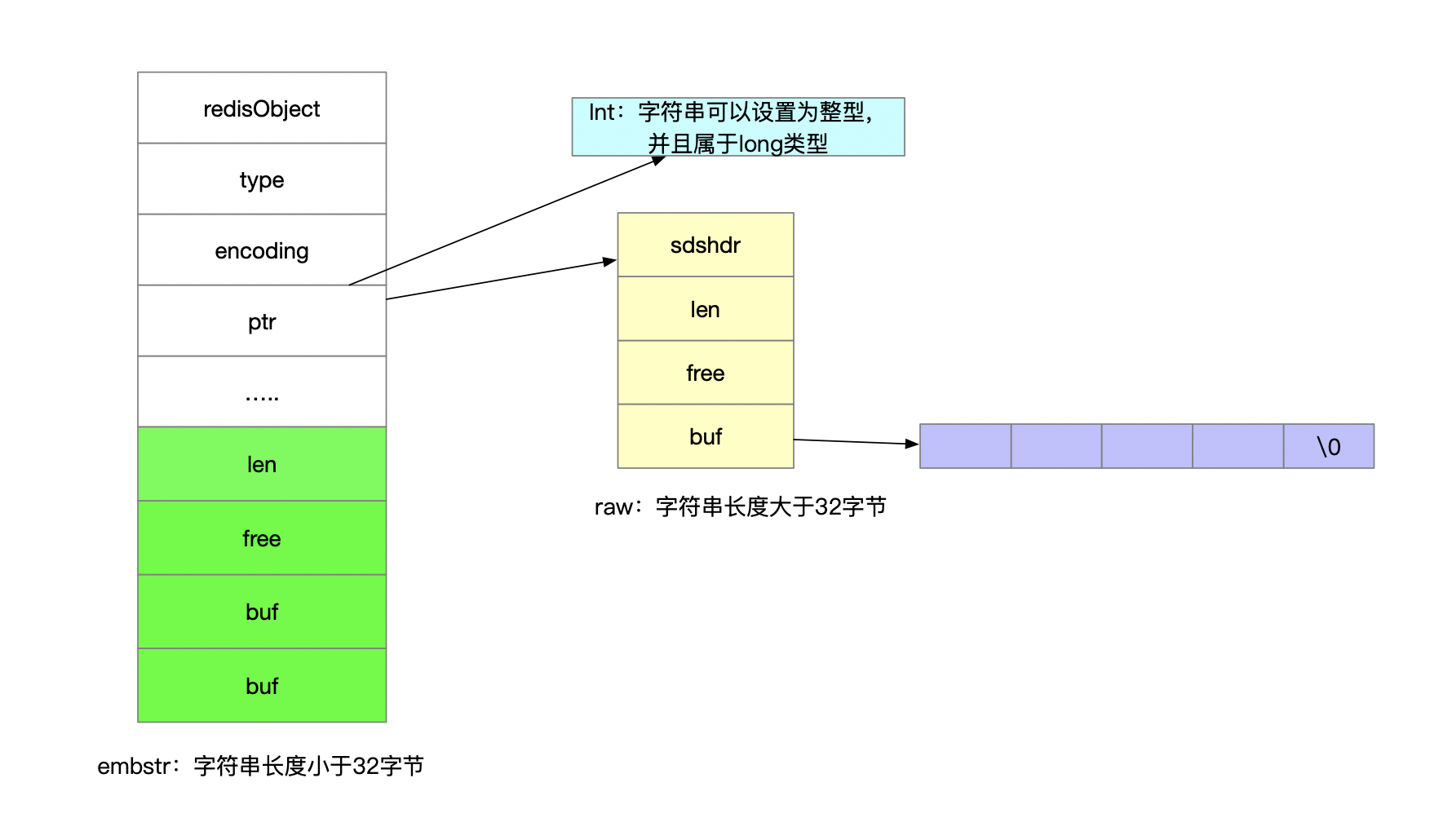 这里需要注意的是出现了一种新的数据结构SDS(简单动态字符串),对应的定义如下(还有flag标记位,不重要,未给出):
这里需要注意的是出现了一种新的数据结构SDS(简单动态字符串),对应的定义如下(还有flag标记位,不重要,未给出):1
2
3
4
5
6
7
8struct sdshdr{
// 记录已使用长度
int len;
// 记录空闲未使用的长度
int free;
// 字符数组
char[] buf;
};
 这里需要注意的是出现了一种新的数据结构SDS(简单动态字符串),对应的定义如下(还有flag标记位,不重要,未给出):
这里需要注意的是出现了一种新的数据结构SDS(简单动态字符串),对应的定义如下(还有flag标记位,不重要,未给出):可以看到底层采用的是字符数组的方式来存放数据,而字符数组采用预分配的机制,也即是空间不够用的时候会对数组长度进行扩展,预分配的好处是减少了内存空间的分配次数, 这在一定程度上可以提升内存的使用效率。另外上面的结构体中我们可以看到其中记录了已使用的长度,这样就使得获取字符串长度的时候时间复杂度是O(1)。
- set:redis的底层采用了intset和hashtable两种数据结构存储,intset可以理解为数组,hashtable就是普通的哈希表,只不过对应的value为null, 只有在集合中的元素都是整数值并且集合中元素的数量不超过512个的时候才会采用intset
- zset:zset在集合数量小于128个并且所有成员的长度小于64字节的时候直接使用zipList进行存储,其中节点中的第一个元素保存数据,第二个保存score,
这样依次按照score从小到大进行存储,其查找复杂度也为
O(n),而当上述条件不满足的时候则直接使用skipList编码来进行存储,对应的结构体如下:1
2
3
4
5
6
7
8
9
10
11
12typedef struct zset {
// 字典,键为成员,值为分值
// 用于支持 O(1) 复杂度的按成员取分值操作
dict *dict;
// 跳跃表,按分值排序成员
// 用于支持平均复杂度为 O(log N) 的按分值定位成员操作
// 以及范围操作
zskiplist *zsl;
} zset;
如上,其对应的dict字段指向一个字典,字典的key为member,value为该member对应的score,zskiplist则是跳表,用于支持O(log N)的查找操作。相较于平衡树,跳表
并不要求太严格的平衡操作,实现上更为粗糙,不过查询效率却能够大大的提高
- list:list底层采用的数据结构为quickList+zipList,它会在长度为空的时候自动删除,具体如下图所示:
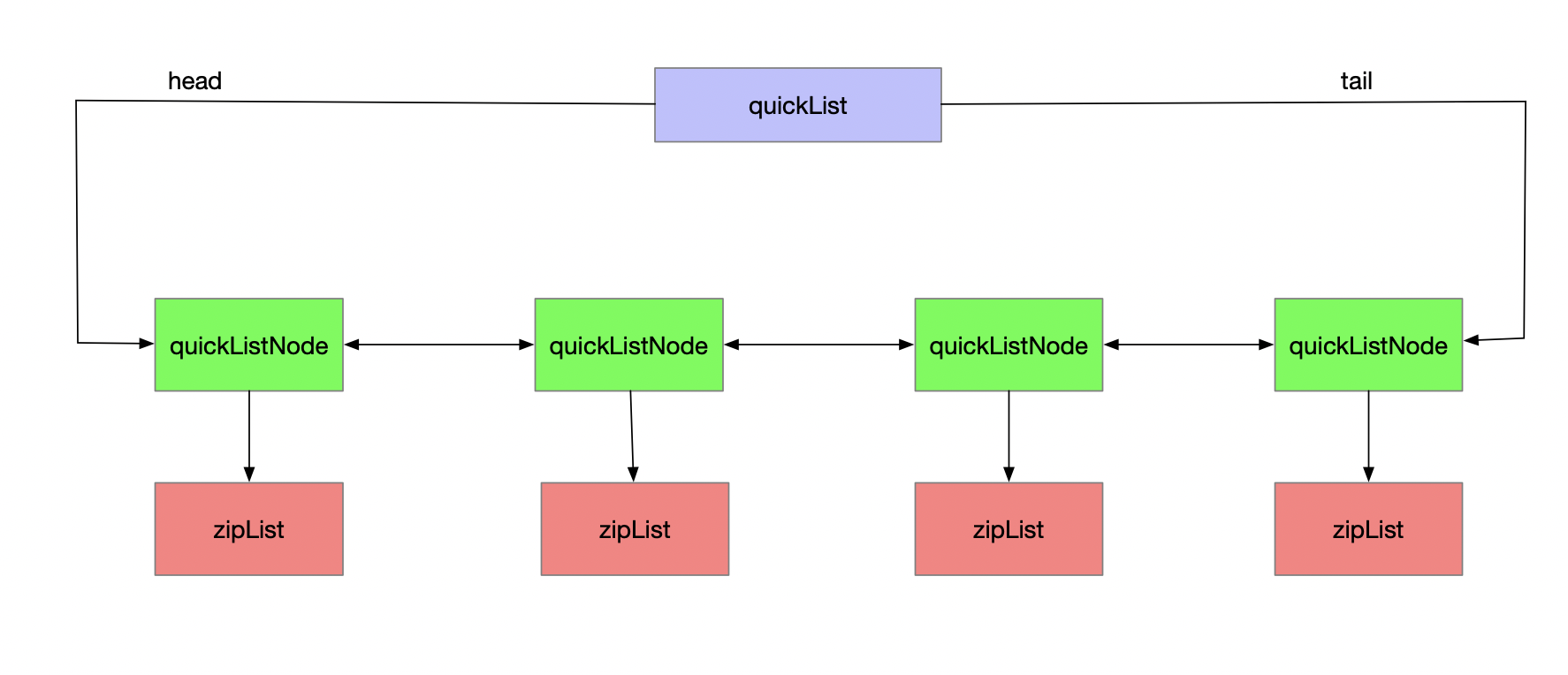 其基本的组成是quickList,其中保存了head和tail指针,这也保证了lpush、rpop操作的时间复杂度是O(1),quickList中的每一个元素由一个quickListNode组成,
其中除了指向前后节点的指针外,还包含了指向zipList的指针,zipList是list中的数据真正存储的地方。采用zipList而不是LinkedList的主要原因是因为LinkedList中的每个
节点都包含了两个指针,这会造成极大的内存开销,而这些开销本身都是没有用的。因此底层采用了zipList这种压缩的数据结构(连续的内存空间分配)有效的减少了内存空间的
浪费。zipList在存储的元素或者其内存空间达到一定程度之后会逆行裂变的操作。
其基本的组成是quickList,其中保存了head和tail指针,这也保证了lpush、rpop操作的时间复杂度是O(1),quickList中的每一个元素由一个quickListNode组成,
其中除了指向前后节点的指针外,还包含了指向zipList的指针,zipList是list中的数据真正存储的地方。采用zipList而不是LinkedList的主要原因是因为LinkedList中的每个
节点都包含了两个指针,这会造成极大的内存开销,而这些开销本身都是没有用的。因此底层采用了zipList这种压缩的数据结构(连续的内存空间分配)有效的减少了内存空间的
浪费。zipList在存储的元素或者其内存空间达到一定程度之后会逆行裂变的操作。 - hash:redis使用字典作为其底层实现(长度、数量小于一定值的时候采用的是zipList来优化内存使用,过大则直接使用hashtable),一个字典中可以包含多个哈希表节点,而每一个哈希表节点中保存了字典中的一个键值对,对应
内存分布如下所示:
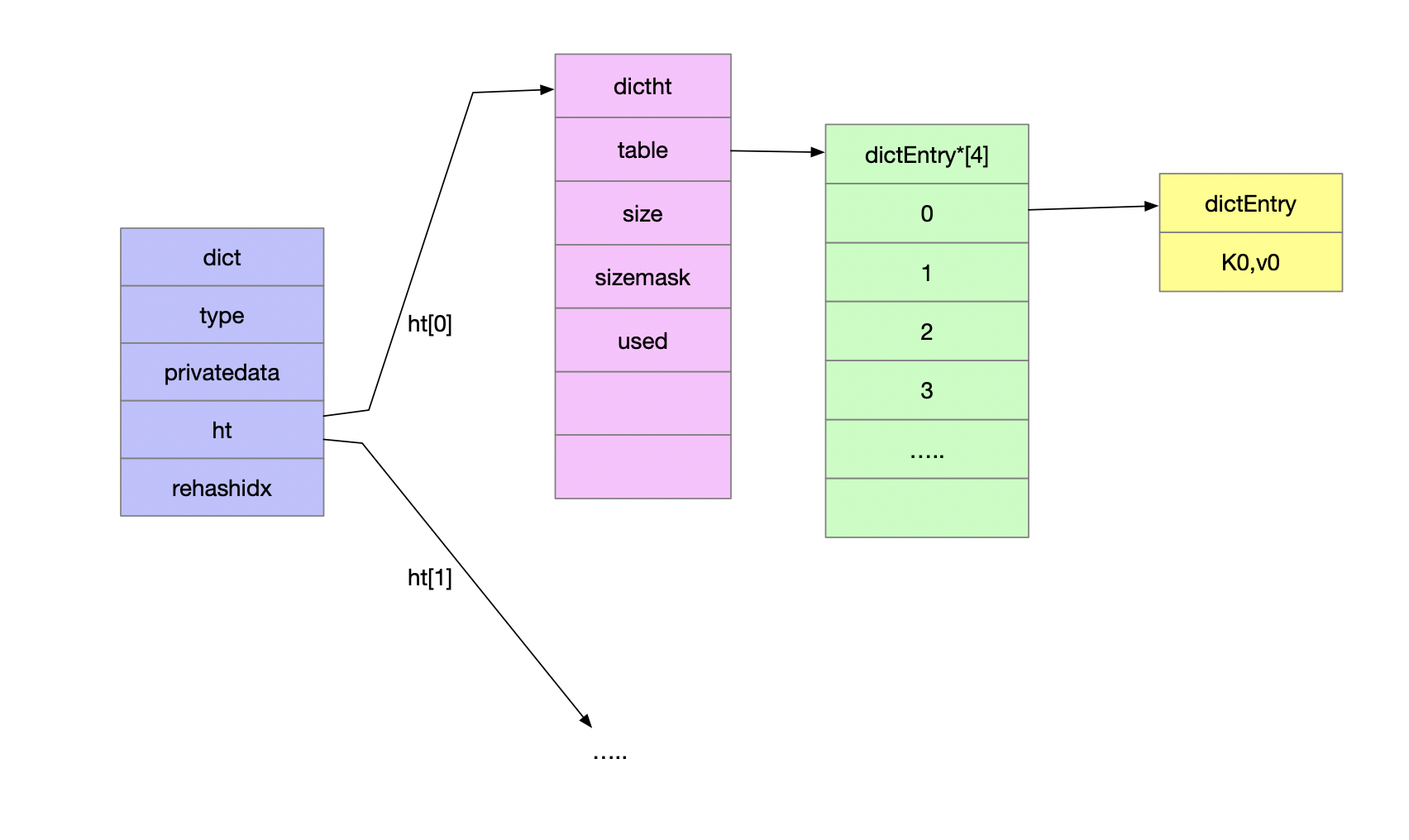 如上图所示会涉及以下几种数据结构:
如上图所示会涉及以下几种数据结构:1
2
3
4
5
6typedef struct dict {
dictType *type; //类型特定函数
void *privdata; //私有数据
dictht ht[2]; //2个哈希表,哈希表负载过高进行rehash的时候才会用到第2个哈希表
int rehashidx; //rehash目前进度,当哈希表进行rehash的时候用到,其他情况下为-1
}dict;
 其基本的组成是quickList,其中保存了head和tail指针,这也保证了lpush、rpop操作的时间复杂度是O(1),quickList中的每一个元素由一个quickListNode组成,
其中除了指向前后节点的指针外,还包含了指向zipList的指针,zipList是list中的数据真正存储的地方。采用zipList而不是LinkedList的主要原因是因为LinkedList中的每个
节点都包含了两个指针,这会造成极大的内存开销,而这些开销本身都是没有用的。因此底层采用了zipList这种压缩的数据结构(连续的内存空间分配)有效的减少了内存空间的
浪费。zipList在存储的元素或者其内存空间达到一定程度之后会逆行裂变的操作。
其基本的组成是quickList,其中保存了head和tail指针,这也保证了lpush、rpop操作的时间复杂度是O(1),quickList中的每一个元素由一个quickListNode组成,
其中除了指向前后节点的指针外,还包含了指向zipList的指针,zipList是list中的数据真正存储的地方。采用zipList而不是LinkedList的主要原因是因为LinkedList中的每个
节点都包含了两个指针,这会造成极大的内存开销,而这些开销本身都是没有用的。因此底层采用了zipList这种压缩的数据结构(连续的内存空间分配)有效的减少了内存空间的
浪费。zipList在存储的元素或者其内存空间达到一定程度之后会逆行裂变的操作。 如上图所示会涉及以下几种数据结构:
如上图所示会涉及以下几种数据结构:其中的type字段为指针类型,其定义了针对特定类型的函数,这里的指针很像是java中的接口一样,通过虚化实现提供了多台的能力。ht为一个数组,通常情况下我们只会使用ht[0],
只有在hash负载过高进行rehash的时候才会使用ht[1],rehashidx则表示了在rehash的过程中的进度,默认为-1(没有进行rehash操作)。哈希表指向的字段为dictht
其具体定义如下:
1 | typedef struct dictht { |
在上述的结构中主要是table指针,该指针指向一个数组,数组的每一个元素又是一个指针,指向了dictEntry结构,对应定义如下:
1 | typedef struct dictEntry { |
上述结构体中需要注意的next指针是用来解决hash冲突的问题。redis采用了渐进式rehash的方式来避免在hash表扩容的时候阻塞时间太久而造成的不可用,具体过程如下:
- 为ht[1]分配空间,让字典同时持有ht[0]、ht[1]两个哈希表
- 将字典中的rehashidx置位为0,标识rehash的正式开始
- 在rehash进行的期间,每次对字典执行添加、删除、查找或者更新操作的时候,程序除了执行指定的操作之外还会将ht[0]中对应的rehashidx下标所标识的数据移过去
- 重复上述操作直到将哈希表中所有的键值对移过去
在渐进式rehash的过程中需要注意的是增加只会在新的哈希表中执行,而删除、修改、查询则会在两个哈希表中进行
redis基本数据结构小结
- string:redis的string是simple dynamic string,相较于c语言里面的string,其最大的特点是预分配、懒回收的策略,所谓的预分配是redis在给string类型的value分配内存空间的时候会多分配一些空间,这样做的好处是string类型的数据在修改长度的时候基本不用再次分配一块内存空间,懒回收则是string在长度减少的那一刻并不会立即回收掉内存
- hash:hash数据结构的实现采用的是hash表,这种数据结构有点类似于java的hash实现,同样对于产生了hash冲突的键也是采用链地址法来解决
- list:redis的list采用了双向链表的数据结构来实现,分别保存了head、tail的指针,这样push和pop的复杂度都是O(1)
- set:set的数据结构类似于hash,只是对应的value统统为null,这和java里面hashset的实现也是类似的
- zset:zset相较于set多了一个score的权重值,其本质是有序链表,其基础的数据结构可以分为ziplist、skipList,在有序链表的长度或者大小比较小的时候使用的是ziplist的数据结构,这种数据结构的好处是节省内存空间来;在有序链表的长度比较长或者数据比较多的时候,则采用了skiplist的数据结构,skiplist这种数据结构本质是针对有序链表做了多级索引的一种结构,这样我们可以在o(lg N)的复杂度内检索到数据,当然删除、修改的复杂度也是这个级别(删除、修改的本质在于检索到数据),这种数据结构的缺点也是显而易见的,那就是会浪费内存空间。
redis集群模式
redis集群模式大概可以分为三种类型:
- 主从:这种模式包含了master和slave两种角色,其中祝数据库提供读写操作,并将写操作导致的数据变化自动同步给从数据库,在从数据库进行同步的时候包含了两种同步的方式:
- 增量同步:这种方式同步的是指令流,主节点会将对自己的状态产生修改性影响的指令记录在内存的buffer中,然后异步的将指令同步到从节点,既然是异步, 必然以带来问题,当祝节点进程突然挂掉之后,就会导致数据的丢失
- 快照同步:这种同步方式首先需要在祝节点上执行bgsave,将内存中的数据全部写到磁盘中,然后将内容全部传递到从节点,从节点清空内存,并加载快照,不过在快照同步的过程中 可能会有新的指令过来,这部分指令则采用增量同步的方式完成,值得一提的是由于redis是单线程,因此在同步数据到磁盘的时候其实是通过fork出一个子进程来完成数据落地操作的。
- 哨兵:上述主从方式解决了高可用的问题,不过需要人工介入来完成主备的切换,哨兵模式实现了类似故障自愈的能力,在主节点不可用的时候,哨兵进程会通过投票的机制将原来的主节点移除, 并选出新的主节点,而客户端进程在链接集群的时候,会首先链接到哨兵,由哨兵告诉客户端祝节点的地址,并在主节点出现问题的时候将这种变化知会到客户端
- cluster模式:在上述两种模式中都解决了数据库高可用的问题,不过很遗憾的是不管是主从还是哨兵其本质都无法将数据分片,来切分到不同的服务器上面,这也带来了一个问题,
当数据量、请求访问量足够大的时候,单机就会出现性能瓶颈。redis集群模式的数据分片采用的是数据分片的方式,一个redis集群包含了16384个槽位,数据库中的每一个键都属于这些槽位中的
一个,同时每个槽位也对应了一个节点,如下演示了一个包含了三个主节点redis集群:
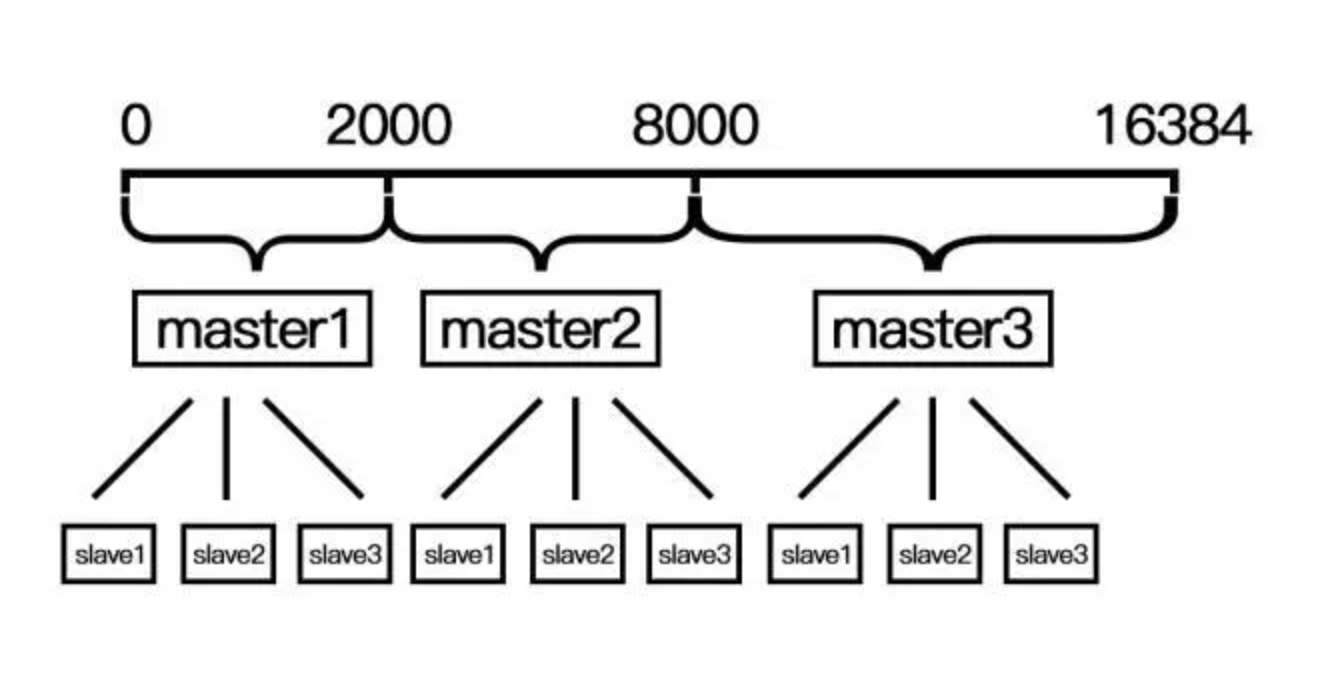 redis集群的客户端在连接到集群中的一个节点的时候会获取这种映射关系,这种关系将会在收到重定向响应(slot发生了迁移导致对应的key发生了迁移)的时候进行更新,如上图所示,
集群模式下的redis更多的是像多套主从集群组成的联邦,只不过slave只会从master同步数据并不会占用槽位。并且集群模式下,所有的主节点承担了客户端所有的读写操作,而对于slave节点仅仅
是做了高可用的保障机制。另外值得一提的是redis集群采用的是流言协议,这可能会在一定的程度上造成数据的缺失。
redis集群的客户端在连接到集群中的一个节点的时候会获取这种映射关系,这种关系将会在收到重定向响应(slot发生了迁移导致对应的key发生了迁移)的时候进行更新,如上图所示,
集群模式下的redis更多的是像多套主从集群组成的联邦,只不过slave只会从master同步数据并不会占用槽位。并且集群模式下,所有的主节点承担了客户端所有的读写操作,而对于slave节点仅仅
是做了高可用的保障机制。另外值得一提的是redis集群采用的是流言协议,这可能会在一定的程度上造成数据的缺失。
 redis集群的客户端在连接到集群中的一个节点的时候会获取这种映射关系,这种关系将会在收到重定向响应(slot发生了迁移导致对应的key发生了迁移)的时候进行更新,如上图所示,
集群模式下的redis更多的是像多套主从集群组成的联邦,只不过slave只会从master同步数据并不会占用槽位。并且集群模式下,所有的主节点承担了客户端所有的读写操作,而对于slave节点仅仅
是做了高可用的保障机制。另外值得一提的是redis集群采用的是流言协议,这可能会在一定的程度上造成数据的缺失。
redis集群的客户端在连接到集群中的一个节点的时候会获取这种映射关系,这种关系将会在收到重定向响应(slot发生了迁移导致对应的key发生了迁移)的时候进行更新,如上图所示,
集群模式下的redis更多的是像多套主从集群组成的联邦,只不过slave只会从master同步数据并不会占用槽位。并且集群模式下,所有的主节点承担了客户端所有的读写操作,而对于slave节点仅仅
是做了高可用的保障机制。另外值得一提的是redis集群采用的是流言协议,这可能会在一定的程度上造成数据的缺失。常用操作
如果说redis中最常用的操作,应该就是获取对应的value这种操作了,大多数的redis客户端都提供了keys、scan这两种模式,对于keys这种操作会一次性将所有的数据查出来,当key的个数过多的时候
会导致服务端处于阻塞的状态,因此该命令是严禁用于生产环境中的,而scan操作则是采用游标的方式迭代返回所有的数据,我们可以设置批量查询的数据量,不过基于scan的操作在对应的value结构发生改变的时候
可能会导致数据重复查询,因此使用的时候需要注意去重的操作,至于为什么会导致数据重复被查询,有兴趣的可以自行查阅文档。
应用
分布式锁
TODO
小结
redis采用了epoll的模型避免了服务端阻塞的性能问题,并且所有的操作都是基于内存的,因此即便是单线程也依然是非常快的,另外单线程带来的好处是避免了线程切换和竞态产生的消耗