flink 学习总结
概述
flink是一款原生的流处理框架,相较于批数据处理,流处理最大的特点就是状态的使用。spark streaming使用的是微批次的处理框架,微批次意味着不同的批次之间没有关系,这一批数据的状态和下一批数据的状态是没有 任何关系的,flink在构建的graph和spark也不一样 ,spark中使用数据作为节点,而数据的处理作为边,边是无状态的,而数据又是一批一批的,因此最终的效果就是整个系统是一个无状态的,而flink在构建graph的时候 使用算子作为节点,数据的话则形成了边,在不同的算子之间流动,因此算子也就具备了状态信息。另外在针对迟到数据进行处理的情况spark streaming并不能很好的处理, 而flink提供了事件时间、处理事件、摄入时间的寓意, 针对迟到数据同样提供了watermark的机制, 也就是水印的能力,可以有效的解决迟到数据的问题。
详解
集群部署
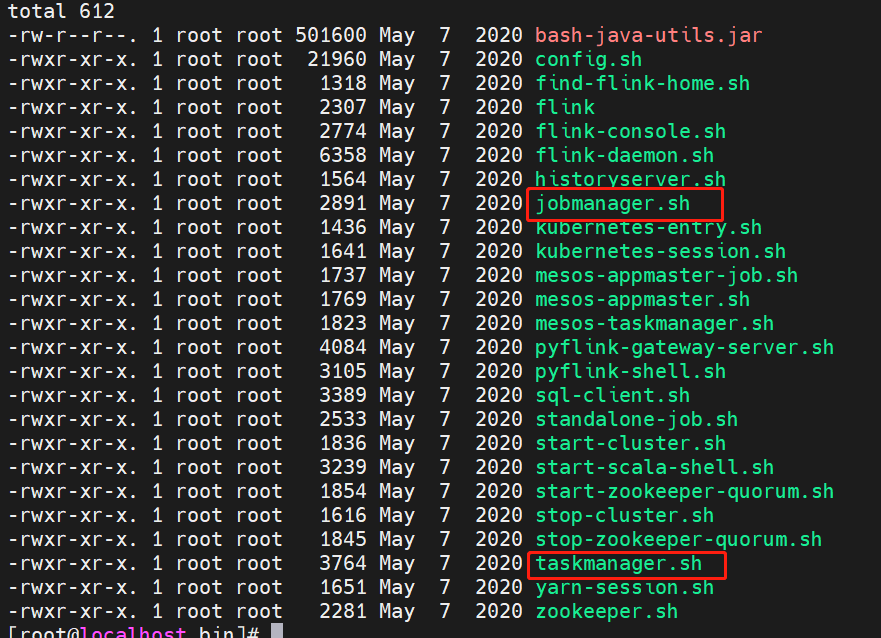
- standalone 模式:在standalone的模式下,有两个核心的脚本分别是jobmanager.sh、taskmanager.sh,除此之外还有conf目录下的masters、slaves两个
配置文件我们首先配置master、slave的地址,然后在各自的节点上将jobmanager.sh和taskmanager.sh运行起来就可以了。
所需脚本:
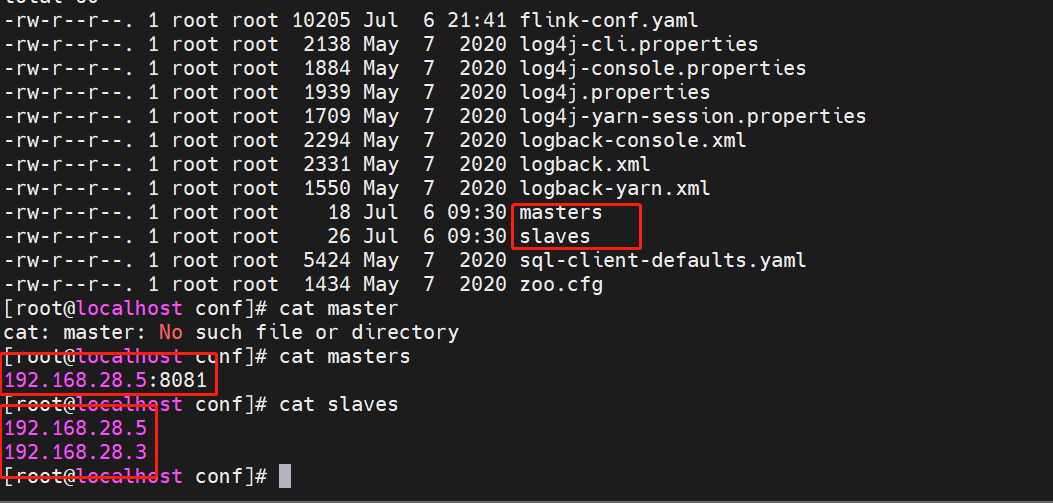
 主从配置信息:
主从配置信息:
 除了上述必须的脚本和参数之外,还有一些配置信息
除了上述必须的脚本和参数之外,还有一些配置信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common : 常用的配置参数
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn/Mesos
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.
# TODO 此处需要手动指定jobmanager的地址
jobmanager.rpc.address: 192.168.28.5
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
# TODO 这里我们可以手动指定jobmanager的堆内存地址,如果运行的是taskmanager的进程的话这个是不生效的
jobmanager.heap.size: 1024m
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
# TODO 这里用来指定taskmanager的内存的大小的,因为一个taskmanager可以存在多个slot,因此这里的内存是会被均分到各个slot上的
taskmanager.memory.process.size: 1728m
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
# taskmanager.memory.flink.size: 1280m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
# TODO 此处定义每一个taskmanager上有多少个slot,这里每一个taskmanager包含了两个slot,因此在作业运行的时候可以提供两个slot
taskmanager.numberOfTaskSlots: 2
# The parallelism used for programs that did not specify and other parallelism.
# TODO 这里用来指定作业运行的时候算子的并行度,其存在覆盖的优先级,算子直接调用setParallelize(n)这个优先级是最高的
# TODO env直接设置并行度次之
# TODO 提交作业的时候,在flink run中指定-p的参数优先级次之
# TODO 最后才是使用flink-conf.yaml中默认的配置
parallelism.default: 1
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#==============================================================================
# High Availability
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#
# high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
#
# high-availability.storageDir: hdfs:///flink/ha/
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#
# high-availability.zookeeper.quorum: localhost:2181
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing TODO 这适合容错相关联的
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
# state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: region
#==============================================================================
# Rest & web frontend
#==============================================================================
# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
#rest.port: 8081
# The address to which the REST client will connect to
#
#rest.address: 0.0.0.0
# Port range for the REST and web server to bind to.
#
#rest.bind-port: 8080-8090
# The address that the REST & web server binds to
#
#rest.bind-address: 0.0.0.0
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
#web.submit.enable: false
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn or Mesos, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#
# taskmanager.memory.network.fraction: 0.1
# taskmanager.memory.network.min: 64mb
# taskmanager.memory.network.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/
# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
#historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
 主从配置信息:
主从配置信息:
 除了上述必须的脚本和参数之外,还有一些配置信息
除了上述必须的脚本和参数之外,还有一些配置信息如果资源不够的话,存在等待的情况,生产环境不推荐
yarn 模式:yarn 模式的情况下,集群是按需启动,具体又分为以下两种
- per job 模式:一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn
申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常
提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大
长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管
理。任务执行完成之后创建的集群也会消失。
 per-job模式启动作业的命令:
per-job模式启动作业的命令:/flink run –m yarn-cluster -c com.wc.StreamWordCount FlinkTutorials.jar,停止作业的时候可以使用yarn -kill,可以参考下面的session停止作业的方式 - yarn session 模式:Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一
块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到
yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作
业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提
交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
 yarn session启动方式:
yarn session启动方式:-n 2 -s 2 -jm 1024 -tm 1024 -nm test -d```,接下来在提交作业的时候 1
可以指定sessionId来提交给特定的session集群,取消作业的方式:```yarn application --kill application_1577588252906_0001
参数说明:
 n个taskmanager,每个taskmanager分配tm的内存,并且每个taskmanager上s个slot,这些是程序运行时执行作业所需要的资源,除此之外,
还有一个tm参数比较重要,用来设置jobmanager的内存大小。
n个taskmanager,每个taskmanager分配tm的内存,并且每个taskmanager上s个slot,这些是程序运行时执行作业所需要的资源,除此之外,
还有一个tm参数比较重要,用来设置jobmanager的内存大小。- per job 模式:一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn
申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常
提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大
长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管
理。任务执行完成之后创建的集群也会消失。
k8s 模式: TODO 此种模式在实际的生产中暂未使用到,因此暂时先不考虑
 per-job模式启动作业的命令:
per-job模式启动作业的命令: yarn session启动方式:
yarn session启动方式: n个taskmanager,每个taskmanager分配tm的内存,并且每个taskmanager上s个slot,这些是程序运行时执行作业所需要的资源,除此之外,
还有一个tm参数比较重要,用来设置jobmanager的内存大小。
n个taskmanager,每个taskmanager分配tm的内存,并且每个taskmanager上s个slot,这些是程序运行时执行作业所需要的资源,除此之外,
还有一个tm参数比较重要,用来设置jobmanager的内存大小。提交作业的流程
通过命令提交的作业是提交给dispatcher,dispatcher会启动jobmanager,并将作业提交给jobmanager,然后由flinkresourcemanager申请资源,如果使用了yarn 或者k8s,这一步会根据需要的资源的数量启动相应数量的taskmanager,这样taskmanager就可以将slot资源注册到对应的flinkresourcemanager,并将资源 提供给jobmanager,jobmanager将executiongraph转移给对应的slot,最后任务就在taskmanager上运行并在不同的slot之间产生数据的分发,整体流程如下:

注意:上面只是一个通用的流程说明(更多的是standalone的模式来提交作业的),而且上述的resourcemanager准确的说是flinkresourcemanager,而不是yarn里面的resourcemanager,这是初学者比较容易 混淆的地方,后面会针对不同的情况进行说明。
上面我们可以看到包含了以下功能组价:
Dispatcher:作业分发器,作业分发器不是一个必要的组件,它可以是一个公共组件,比如我们在standalone的模式下, 提交作业的方式就是调用Dispatcher对应的接口来实现的,再比如我们还是在standalone的模式下,在命令行的模式下 提交作业的方式也是调用Dispatcher的接口来完成的。
Jobmanager:作业管理器
- 用来接收待执行的作业,该作业包含了JobGraph、LogicalDataflowGraph,并包含了打包的类库、三方依赖等信息
- 控制一个作业执行的主进程,不同的作业由不同的控制器控制
- JobManager会把JobGraph转换成ExecutionGraph,此时这个图就包含了所有可以并发执行的任务
- JobManager会向FlinkResourcemanager请求执行任务的必要的资源,也就是Taskmanager上面的Slot,一旦获取到了足够的资源就会将subtask分发到对应的slot上面
- 在作业的执行过程中JobManager负责需要中央协调的工作,比如checkpoint的协调
总结: 关于jobmanager,我们在ui界面上提交的时候可以预览的就是execution graph,包含了算子合并之后,并行度调整之后的作业的信息,jobmanager会将这些subtask分发给taskmanager的slot执行,当然这里slot的申请是需要flink的flinkresourcemanager来向taskmanager来申请的,flinkresourcemanager会告诉jobmanager这些slot所在的节点和槽位信息,从而jobmanager就可以将作业分发到相应的节点。 jobmanager和taskmanager存在心跳信息,用来监控作业运行,taskmanager之间存在数据的交互,因为可能存在shuffle等各种操作,对应的任务运行在不同的taskmanager的不同的slot中。
FlinkResourcemanager:资源管理器,FlinkResourcemanager和Yarn的Resourcemanager是两码事,我们使用Yarn的方式提交作业来说明,
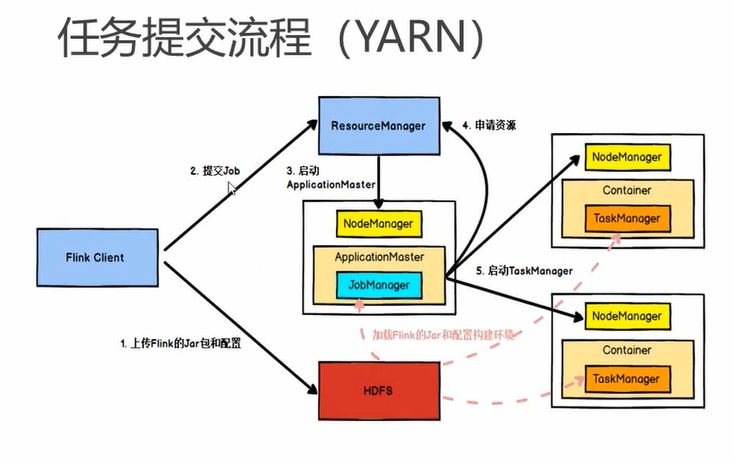 如上图所示,我们在yarn的per-job模式下提交作业的流程是:
如上图所示,我们在yarn的per-job模式下提交作业的流程是:- 上传作业到hdfs
- flink client提交作业(在hdfs上的作业)到yarn集群的resourcemanager(注意这里的rm是yarn的rm),yarn的resourcemanager(封装了之前提到的dispatcher的能力)收到请求之后,会向yarn的一个nodemanager启动一个applicationmaster进程(这是yarn的概念)(可以将applicationmaster看做一个虚拟机)
- applicationmaster会启动一个Flink的jobmanager(内部封装了一个flinkresourcemanager),其内部的flinkresourcemanager会向yarn的resourcemanager申请资源
- yarn的resourcemanager在收到请求之后会在yarn的nodemanager上启动一些container,并将Flink的taskmanager运行起来,然后Flink的taskmanager会将资源的信息注册到Flink的jobmanager的flinkresourcemanager上,接下来Flink的Jobmanager将JobGraph转换成ExecutionGraph,并将对应算子的对应的subtask分发到taskmanager的slot中执行
Taskmanager:任务管理器,taskmanager主要是用来给jobmanager提供slot资源的,也就是真正干活的
 如上图所示,我们在yarn的per-job模式下提交作业的流程是:
如上图所示,我们在yarn的per-job模式下提交作业的流程是:并行度
算子的子任务的个数叫做并行度,同一个算子的不同的子任务会被分配到不同的slot上,不同的算子的子任务是可以共享slot(这样一个slot可以保存整个作业的pipeline,不存在一些跨节点的网络开销), slot更多的是内存等计算资源(cpu、内存:这是核心资源,cpu的话并不是真正意义上的隔离,对于cpu来说因为存在分时复用,所以资源并不能完全隔离,不过要想完全隔离的话其实可以将slot数量设置 的比cpu的核心数少,这样每一个slot至少可以占用一个cpu,也就不会存在cpu的分时复用问题了)。taskmanager上面的slot的数量代表了一种能力,而并行度则是针对作业来说动态的需要的资源。

最终在taskmanager中的slot中运行的结果如下:

通常情况下我们指定作业的并行度有几种方式:
- 算子中直接调用
.setParallelism(n)就可以设置某个算子的并行度,此种优先级是最高的情况 - env中调用
.setParallelism(n),这种方式将会给作业中没有设置并行度的算子设置一个并行度,相较于算子级别的并行度设置,这种情况又次之 - 提交作业的时候指定命令行参数-p来设置并行度,此种情况优先级再次降低
- 最后如果我们没有在作业中设置并行度,也灭有在提交作业的时候设置并行度,那么将会使用flink-conf.yaml中的默认的并行度作为当前作业的并行度
运行一个作业所需的slot的个数就是作业的最大并行度,不过这种情况有一个前提,那就是我们没有针对算子设置slotGroup,此时所有的算子默认都在一个slotGroup中,对应的slotgroup为default, 在给某一个算子设置了slotGroup之后,那么不同的group之间是无法实现slot的共用的,因此所需的slot的数量是sum(Max(slotgroup(p))),也就是说我们要取每一个slotgroup的最大并行度, 然后将所有的slotgroup的最大并行度进行求和。slotgroup具备继承的特征,后面的算子在没有设置slotgroup的情况下,会从前面的算子继承过来。
任务链优化
前面并行度的设置决定了作业运行所需的最小的slot资源,这些slot中会运行对应算子的subtask,那一个作业有多少个subtask呢? 在任务链没有优化的情况下,我们很容易得到作业在提交到slot上最终会生成多少个subtask:sum(parrelism(operator)), 也就是将每一个算子的并行度 进行求和最终得到的数量就是生成的subtask的数量。这么计算一个job的subtask是有问题的, 这就不得不提另外一个比较重要的概念:任务链优化。
不过在了解任务链优化之前,有必要先看一下Flink中作业图的转换:

上图中我们可以看到作业在提交到jobmanager的时候,会由jobmanager进行优化,将符合条件的多个operator串起来形成一个大的operator,这个过程的优化就叫做任务链优化。 而后的excutionGraph是根据合并后的Jobgraph生成的。这样做的好处是避免了无谓的网络、内存的开销。上面图的转换具体如下:
![]()
不过算子是否可以合并存在一定的条件,如下类型的算子是不可以合并的:
- 算子的并行度不同
- redistribute的操作:如keyBy、广播、shuffle(完全随机,区别于rebalance)、rebalance(和keyby是一种机制)keyBy是按照key进行分发, rebalance是轮训的方式进行分发(相当于spark里面的宽依赖),rescale的数据再均衡和rebalance略微不同,rescale会直接在源侧进行数据的分区,因此上下游的笛卡尔积比较小, 而rebalance则是上下游直接笛卡尔积,shuffle的更彻底,因此从数据发送的流程来看rescale可以是rebalance的一种优化,从shuffle的处理来看rebalance则是rescale的一种优化。 spark里面的shuffle可以认为是洗牌,因为其是微批次的处理方式,这一批数据到来之后shuffle一下,而flink里面的shuffle则类似于发牌。也就是说spark的shuffle是批收而后发, flink的shuffle是直接发
上面我们看到了对于并行度相同的one-to-one且分布在同一个slot中的算子可以被优化成一个operator,如下:

上面的方框代表subtask,圆框代表operator,如果不希望合并,可以设置共享组,不过这种方式会要求新的slot资源,
可以通过rebalance、shuffle做一个重分区,这样就可以打破算子的合并,还以调用算子的disableChaining(),
代表了该步操作和前后的算子都不合并,还可以使用startNewChain来单独和前面断开合并operator。
上面我们针对slot和task做一下总结,并行度决定了需要的slot的数量,也决定了subtask的数量,不过这是从纵向的维度上决定的, operator chain则是从横向的维度上决定了subtask的数量。
算子解析
flink中的算子可以分为3大类:source、transform、sink,另外Flink中使用的JavaBean一般都需要定义一个无参的构造函数,因为flink是一个分布式的系统, 涉及到很多的网络传输,那就必然设计对象的序列化、反序列化,我们知道在java中对象的序列化、反序列化都需要的就是包含一个无参的构造函数。
source算子
source算子并没有什么特别之处,我们常见的有sock或者文件类型的source,如果我们要自己定义一个类型的Source的话,只需要实现对应的接口并调用 env的addDataSource方法就可以从对应的source收集数据了。
问题:kafka读取数据的时候如果指定消费者组,并且将auto.commit.offset置为false,那么首次消费数据的时候就会出现找不到offset的问题, 这个是不是可以指定消费的规则为auto.offset.reset为earlist或者latest来避免,startFromConsumerGroup和auto.offset.reset的优先级是什么???
transform算子
在flink中,一些transform算子的一些函数包含了T、R两个泛型的函数意味着类型可能会发生改变,因此在函数的内部包含了一个collector, 用于收集数据并发往下游,对source来说也是这样子的, 而函数只有一个T的意味着类型或者数量不会发生改变(像map、filter), 因此就不需要collector实现数据的收集。下面我们看一下Flink中一些常用的算子:
单流:
keyBy:keyBy是分区操作,不是分流操作,分区意味着同一个区的数据可以包含多种(当然一种数据只会在一个分区,也就是分区和数据类别是1:n的关系), 分流操作意味着同一个分区一般是按照一个规则分成了一条新的流,新的流中只包含一种符合特定规则的数据,另外datastream只有keyBy没有groupBy (这是因为flink是流式操作的,不是批式,批式数据才有groupBy的操作,因为是批式,也就意味着有了一批数据,因为是流式所以并没有办法在同一时刻获取一批数据, 这两个算子的含义有点类似于keyBy是发牌,groupBy是洗牌),并且reduce或者sum、max、min等操作也需要在groupBy或者keyBy之后才有意义。
- 字段选择:对于flink的KeyBy常见的字段选择有针对Tuple的位置的选择、针对JavaBean的字段的选择,或者自定义KeySelector来指定特定Key的选择。
上面调用了KeyBy之后DataStream就转换成了KeyedStream,因此如果想要将KeyedStream继续转换成DataStream需要调用相关的算子,常见的如下:
- 统计函数:min、max、sum、minBy、maxBy,这些算子我在最早看到时候有些疑问:数据经过keyBy之后,会分到一个分区,但是分到同一个分区的数据会存在多种类型的key,那么 当我使用sum等各种统计算子的时候,是不是把这个分区的所有数据进行sum呢?答案并不是,keyBy只是将原来大堆的数据切分成小堆,但是sum的话是小堆里面相同key值的sum操作。 另外minBy、maxBy在遇到的数据不管是Tuple还是javaBean,其将会把这个javabean对应的key的所有的其他字段都记录,而min、max只会记录第一条记录的这些无关字段,以 User(sex, name, age)这种类型的java bean为例,如果我们使用keyBy(“sex”).max(age)处理流式数据,那么得到的sex是准确的,age也是准确的,但是name是流过来的第一个 记录的name,而minBy、maxBy的话name字段则是准确的信息。
- 聚合函数:前面的统计函数只是针对一个字段进行统计,如果我们希望针对多个字段进行统计的话,可以使用reduce函数
RichFunction:我们以filter、map、flatmap为例,除了我们常见的FilterFunction、MapFunction、FlatMapFunction之外还有RichFilterFunction等各种RichFunction 这里的rich是只除了提供基本的操作之外,还提供了状态相关的操作,比如可以获取上下文等信息(这里的状态可以从reduce函数来看,reduce要求记录上一个记录的状态, 并和下一个记录进行一定的操作;map、filter则看不出来有什么状态),如下图所示:
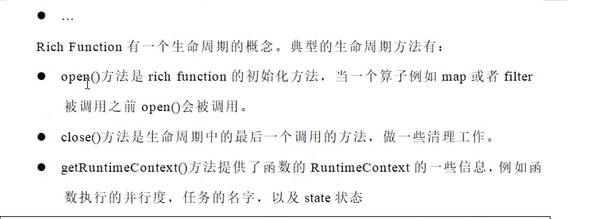 open是一个初始化的过程,在执行的时候会创建一些对象分部到slot中去等待数据的到来,这个open方法就是用来在subtask执行的时候对其进行初始化的操作,
注意这里是subtask,不是构造函数,如果是构造函数的话,会初始化并序列化到各个slot里面,比如我们在jobmanager创建了一个数据库连接对象,并传入到算子的构造函数中
,这样做就是有问题的,因为slot所在的taskmanager并没有建立一个和数据的连接,因此即便被反序列化出来也是无法使用的。
richfunction是一个抽象类,open、close是只会执行一次的方法,并且其执行的线程和正常的数据处理是不同的线程,因此open方法的阻塞并不会导致处理数据线程的阻塞,
也正因为如此,我们如果要在process数据的时候使用open方法初始化对象,还需要等待open方法完成对象的初始化,否则可能会出现在使用的时候空指针的问题。
open方法完成资源的初始化可以极大的节约资源,比如map函数里面如果来一个数据就打开一个数据库连接会极大地消耗资源,而open、close方法则是可以避免重复开启、关闭数据源的过程。
不过open和close一共执行的次数和当前任务的并行度是一致的。也就是说open、close的执行是分区执行一次,里面的具体的方法的执行则是一个记录一次。
open是一个初始化的过程,在执行的时候会创建一些对象分部到slot中去等待数据的到来,这个open方法就是用来在subtask执行的时候对其进行初始化的操作,
注意这里是subtask,不是构造函数,如果是构造函数的话,会初始化并序列化到各个slot里面,比如我们在jobmanager创建了一个数据库连接对象,并传入到算子的构造函数中
,这样做就是有问题的,因为slot所在的taskmanager并没有建立一个和数据的连接,因此即便被反序列化出来也是无法使用的。
richfunction是一个抽象类,open、close是只会执行一次的方法,并且其执行的线程和正常的数据处理是不同的线程,因此open方法的阻塞并不会导致处理数据线程的阻塞,
也正因为如此,我们如果要在process数据的时候使用open方法初始化对象,还需要等待open方法完成对象的初始化,否则可能会出现在使用的时候空指针的问题。
open方法完成资源的初始化可以极大的节约资源,比如map函数里面如果来一个数据就打开一个数据库连接会极大地消耗资源,而open、close方法则是可以避免重复开启、关闭数据源的过程。
不过open和close一共执行的次数和当前任务的并行度是一致的。也就是说open、close的执行是分区执行一次,里面的具体的方法的执行则是一个记录一次。
多流
- split:有点类似于keyBy操作,会生成一个splitStream,split相当于给原来的流盖一个戳,接下来必须要跟上一个select来将数据选取出来,如下图所示:
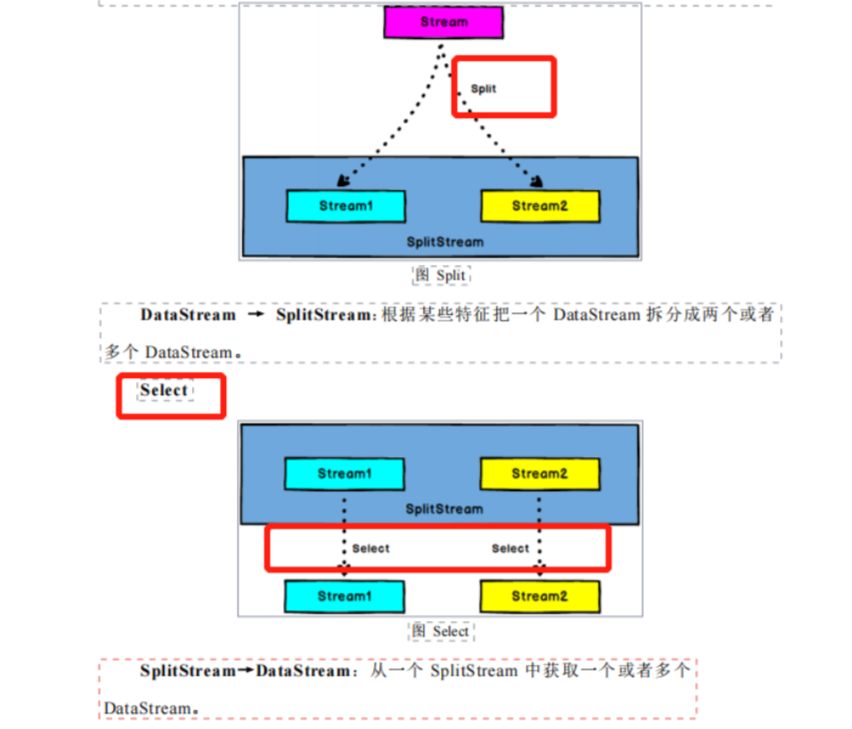 针对流进行打标的代码如下:
针对流进行打标的代码如下:
 这个代表同一条数据我可以给他安排多个标签,这样后面select可以更多元化,select也可以传入多个标签,形成一个组合来筛选数据,不过select是取得并集
这个代表同一条数据我可以给他安排多个标签,这样后面select可以更多元化,select也可以传入多个标签,形成一个组合来筛选数据,不过select是取得并集 - connect:调用connect这一步并非真正的合并成了一个流,因为每个流的类型还是保持不变的,你的还是你的,我的还是我的,只有在调用了coMap这一步操作才是合并流的一个过程,如下:
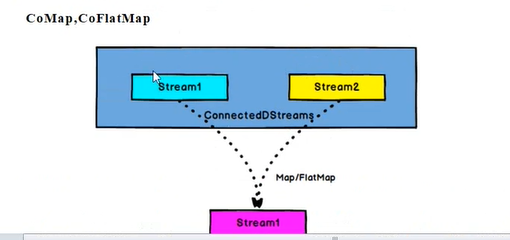
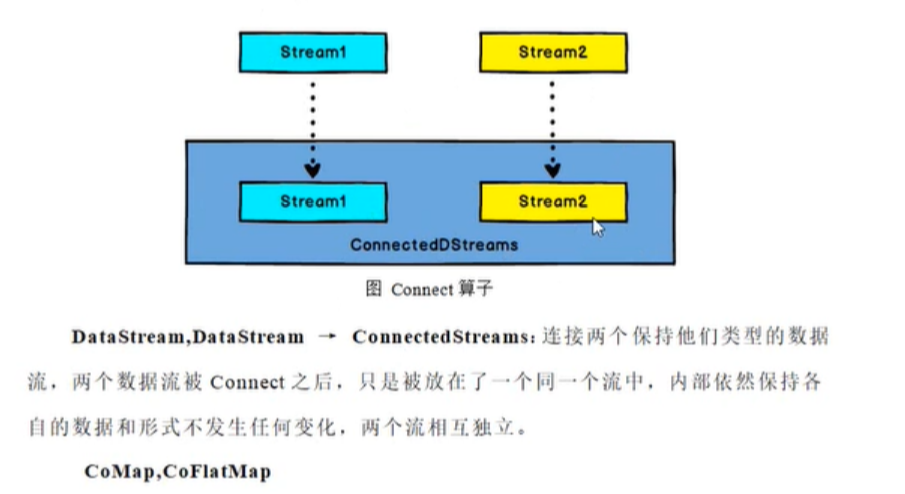 调用coMap之后数据就变成了下面的结果:
调用coMap之后数据就变成了下面的结果:
- union:连接两条流除了connect之外,还可以是union,不过connect是非常方便的一种方式。connect只可以连接两条流,不过union合并的流要求流的类型一致。
- split:有点类似于keyBy操作,会生成一个splitStream,split相当于给原来的流盖一个戳,接下来必须要跟上一个select来将数据选取出来,如下图所示:
 open是一个初始化的过程,在执行的时候会创建一些对象分部到slot中去等待数据的到来,这个open方法就是用来在subtask执行的时候对其进行初始化的操作,
注意这里是subtask,不是构造函数,如果是构造函数的话,会初始化并序列化到各个slot里面,比如我们在jobmanager创建了一个数据库连接对象,并传入到算子的构造函数中
,这样做就是有问题的,因为slot所在的taskmanager并没有建立一个和数据的连接,因此即便被反序列化出来也是无法使用的。
richfunction是一个抽象类,open、close是只会执行一次的方法,并且其执行的线程和正常的数据处理是不同的线程,因此open方法的阻塞并不会导致处理数据线程的阻塞,
也正因为如此,我们如果要在process数据的时候使用open方法初始化对象,还需要等待open方法完成对象的初始化,否则可能会出现在使用的时候空指针的问题。
open方法完成资源的初始化可以极大的节约资源,比如map函数里面如果来一个数据就打开一个数据库连接会极大地消耗资源,而open、close方法则是可以避免重复开启、关闭数据源的过程。
不过open和close一共执行的次数和当前任务的并行度是一致的。也就是说open、close的执行是分区执行一次,里面的具体的方法的执行则是一个记录一次。
open是一个初始化的过程,在执行的时候会创建一些对象分部到slot中去等待数据的到来,这个open方法就是用来在subtask执行的时候对其进行初始化的操作,
注意这里是subtask,不是构造函数,如果是构造函数的话,会初始化并序列化到各个slot里面,比如我们在jobmanager创建了一个数据库连接对象,并传入到算子的构造函数中
,这样做就是有问题的,因为slot所在的taskmanager并没有建立一个和数据的连接,因此即便被反序列化出来也是无法使用的。
richfunction是一个抽象类,open、close是只会执行一次的方法,并且其执行的线程和正常的数据处理是不同的线程,因此open方法的阻塞并不会导致处理数据线程的阻塞,
也正因为如此,我们如果要在process数据的时候使用open方法初始化对象,还需要等待open方法完成对象的初始化,否则可能会出现在使用的时候空指针的问题。
open方法完成资源的初始化可以极大的节约资源,比如map函数里面如果来一个数据就打开一个数据库连接会极大地消耗资源,而open、close方法则是可以避免重复开启、关闭数据源的过程。
不过open和close一共执行的次数和当前任务的并行度是一致的。也就是说open、close的执行是分区执行一次,里面的具体的方法的执行则是一个记录一次。 针对流进行打标的代码如下:
针对流进行打标的代码如下:
 这个代表同一条数据我可以给他安排多个标签,这样后面select可以更多元化,select也可以传入多个标签,形成一个组合来筛选数据,不过select是取得并集
这个代表同一条数据我可以给他安排多个标签,这样后面select可以更多元化,select也可以传入多个标签,形成一个组合来筛选数据,不过select是取得并集 调用coMap之后数据就变成了下面的结果:
调用coMap之后数据就变成了下面的结果:

在datastream调用map、flatmap不会改变流的类型,而调用了keyBy会返回keyedstream、split会返回splitedstream、connect会返回connectedstream, 上述转换成特定的stream之后都有相应的操作来将流转换成原来的datastream。
类型推断:我们在使用flink的算子来处理数据的时候,有些时候会使用lambda表达式来处理简化处理的函数书写,这时候可能会出现类型推断不出来的问题,可以加上returns来指定Typehints
sink算子
同source算子一样,sink算子也没有什么好说的,如果有的话就是记住一个通用的算子addSink()。另外sink中包含的泛型是上游流的泛型, 并不是写到下游的泛型,因此在写到下游类似于kafka的时候需要自定义序列化器
算子总结: 算子操作总结:
1、flink操作的java bean必须包含一个默认的无参构造方法,因为flink的keyBy会使用反射来反序列化对象,如果不指定无参的构造函数会报错, 因此在flink中使用javabean并设置默认的构造函数是一个良好的习惯。经发现并行度改变或者slotgroup改变如果java bean没有无参的构造函数的话也不会影响程序的执行, 目前只有在keyBy的时候发现存在这种情况。
2、流的类型发生改变的transform算子:keyBy->keyedStream, split -> splitedStream,connect -> connectedStream, 这些个生成的流继承了Datastream,可以通过后续的算子再次将这些流转换成普通的Datastream,对于keyBy可以使用group、reduce、对于split可以选择select, 对于connect可以使用map1、map2来完成流的类型的转换
3、在flink中有些算子包含了T、R两个泛型,并且在返回R的时候,存在多个对象,这种情况下一般会内置collector来实现对数据的收集,而如果仅仅是数据类型可能改变或者不变, 但是数据的数量并不会发生改变,这种类型的算子一般不会包含collector。更一般的自定义source也是要包含一个collector对象: 一言以蔽之,collector可以实现收集多个数据的能力,因此只要可以产生多条数据的算子一般都会包含collector对象
4、在flink中,原生的datastream并没有groupBy的算子,只有keyBy的算子,这个其实也好理解, 因为flink是流式模型,对于流来说数据不会一下子就到,因此在数据无法全部在一个时刻收集到的情况,使用groupBy是没有什么意义的,而keyBy更多的像是一个发牌的过程, 这样一个key只会被发往下流的一个分区,而一个分区可能会收到多个Key(因为hashcode/n得到的分区相同,这里我们说的分区其实是下游的subTask), 不过在使用后续算子如sum等操作的时候,如果多个key相同的数据被发往一个分区,最后在做reduce的时候并不是针对一个分区做一次,而是针对key值相同的做这个运算, 其他字段则选择最小的字母顺序或者数值最小的来填充(这是sum)
5、flink 中 split算子用于实现对流的打标记,后续可以通过select将标记的流再次筛选出来,可以给一个流打多个标记,不过select选择同一个流的多个标记的时候 最终的结果并不会重复计算,这已经通过代码进行了验证
6、connect算子:connect之后,两条流看起来合并成一条流了,不过真实的情况是并没有立即合成一条流,原因是两条流的类型可能不同,因此需要分别调用两条流的map函数, 将两条流转换成一种类型的流,connect之后可以调用的算子和datastream一样,只是在内部传入的传入的函数不再是普通的map、flatmap等操作了, 而是coMap等操作,co的含义是connect的意思,之后这两条流就会直接合并成一条流
window操作
在流数据中框出来一批数据的过程就叫做开窗,区别于spark微批次处理流程,flink的窗口更多的是一个桶的机制,这个桶用来收集数据的到来(等待触发计算的到来), 因此同一个时刻是可以存在多个桶的(前面一个桶的触发计算的时机还没有到,新的数据又不属于前面的桶,就会再开一个新的桶)。这样做的好处就可以处理乱序数据了。 以上开桶的操作不论是事件时间还是处理时间都是有的。,窗口分类大致如下:
时间窗口(timewindow)
- 滚动窗口:窗口长度固定,彼此不重叠,只需要windowsize参数就可以了
- 滑动窗口:窗口长度固定,滑动距离固定,可以重叠
- 会话窗口:会话窗口指代的是事件在发送的时候,中间有一段没有了,比如打电话,中间挂了30分钟再次拨通电话,那么两次会话之间就存在了30min的时间间隔,
我们称之为session gap(其本质也是一个时间区间,而且是最小的时间区间,也就是说两个事件之间的时长只要大于session gap了,那么就会算作不同的窗口了)
下图代码中我们按照user的id进行keyBy,user1、user2、user3对应了3个session,即便是user1、user2、user3恰好被分到同一个分区了,其也是3个不同的session,
因为key就是一个session的唯一标识,也就是说user1是一个session1,user2是一个session2,user3是一个session3:

计数窗口(countwindow)
countwindow比较简单,在实际的生产中用的也比较少,因此这里按下不表了,略微提一句,countwindow是数量足够的时候才会执行后续的操作,数量不够的时候只会进行等待。

window API:
window、timewindow、countwindow,这个操作必须要keyedstream上才可以使用,不过在datastream上是可以使用windowall的方法,不过这个带来的效果是相当
于datastream的.global方法,将数据发往下游算子的第一个分区了,也就是下游算子并行度不生效了,在keyed之后生成了keyedstream,其是datastream的子类,
(因此也包含windowall的方法),在使用了这个算子之后也会发往下游的一个分区,不过其是触发一个分区的计算之后,再次发送到下一个分区,实现数据在分区间的来回穿梭。
 keyBy之后使用windowAll会让原本落在某一个分区的key再次采用roundrobin的机制在不同的slot之间流转,
就上述而言,本来字符串s通过Key之后会落在其中的一个slot,而使用了windowAll算子的话就会在原来KeyBy的基础上叠加windowAll的效果。
keyBy之后使用windowAll会让原本落在某一个分区的key再次采用roundrobin的机制在不同的slot之间流转,
就上述而言,本来字符串s通过Key之后会落在其中的一个slot,而使用了windowAll算子的话就会在原来KeyBy的基础上叠加windowAll的效果。
窗口函数
窗口分配器是在slidewindow、thumblewindow、sessionwindow、globalwindow等各种窗口中实现数据落桶的一种机制。具体如下
 通过窗口分配器实现KeyedStream向windowstream的转换,
一个完整的window除了窗口函数之外还要有窗口函数才可以结束,此时实现的效果是windowstream向datastream的转换。
通过窗口分配器实现KeyedStream向windowstream的转换,
一个完整的window除了窗口函数之外还要有窗口函数才可以结束,此时实现的效果是windowstream向datastream的转换。
 增量聚合函数是在当前的时间窗口内,来一条数据计算一次并更新状态直到最后真正的截止时间,才会完成一次数据的输出,
这个区别于keyBy之后的reduce,那种是来一条计算一次并且输出一次,window开窗之后只会在窗口完成之后输出一次数据。
全窗口函数则属于攒一批数据然后进行相应的聚合操作,最后再输出一次结果。在使用了window开窗之后生成的windowstream本质上还是keyedstream,
因此依然可以使用min、max等聚合算子,不过这个时候的聚合算子是针对窗口来说的,而且是属于增量聚合(不知道这个时候使用这些聚合算子的话数据是不是还是会实时的打印 待测试,
猜测应该不会实时打印,也是窗口闭合的时候打印一次)
增量聚合函数是在当前的时间窗口内,来一条数据计算一次并更新状态直到最后真正的截止时间,才会完成一次数据的输出,
这个区别于keyBy之后的reduce,那种是来一条计算一次并且输出一次,window开窗之后只会在窗口完成之后输出一次数据。
全窗口函数则属于攒一批数据然后进行相应的聚合操作,最后再输出一次结果。在使用了window开窗之后生成的windowstream本质上还是keyedstream,
因此依然可以使用min、max等聚合算子,不过这个时候的聚合算子是针对窗口来说的,而且是属于增量聚合(不知道这个时候使用这些聚合算子的话数据是不是还是会实时的打印 待测试,
猜测应该不会实时打印,也是窗口闭合的时候打印一次)
全窗口函数需要在window之后使用apply、process方法才可以,而不是增量处理函数中的的reduce、aggregate等操作。
总结:
1、 countwindow中的window在keyBy之后需要有特定的key满足了count才会执行后续的操作,并不是在原始流中满足了count就会输出,这个在测试后的时候发现的。
2、 flink默认根据processingtime来划分window,不是eventtime,如果希望根据eventtime来划分窗口需要在env中进行单独的设置
3、 window API汇总如下:
 上面allowLatenessData方法在窗口已经触发计算之后,再次触发的方式是每来一条迟到数据就会触发一次计算,这样会频繁输出临时的中间结果,生产环境不建议使用,
也就是说原来的桶已经关闭了,不过不确定allowLatenessData是否会将迟到的数据叠加到原来的状态上,可以代码实操一下 待测试
windowstream针对key和window进行计算,windowstream和keyedstream并没有什么关系,keyedstream是针对key进行的计算,其流转图如下所示:
上面allowLatenessData方法在窗口已经触发计算之后,再次触发的方式是每来一条迟到数据就会触发一次计算,这样会频繁输出临时的中间结果,生产环境不建议使用,
也就是说原来的桶已经关闭了,不过不确定allowLatenessData是否会将迟到的数据叠加到原来的状态上,可以代码实操一下 待测试
windowstream针对key和window进行计算,windowstream和keyedstream并没有什么关系,keyedstream是针对key进行的计算,其流转图如下所示:
![]()
水印
开窗操作默认是processtime语义,事件时间语义需要在env里面进行设置,并且需要指定流里面的bean的哪个字段来提取时间戳(这一点很重要:assigntimestampandwatermark)。
这里插一句,不管是processtime还是eventtime我们以10s的窗口为例,窗口是从0s10s还是1s11s,或者5s到15s呢,也就是说窗口的起始时间怎么确定,这个可以看一下window相关的代码:
 这里可以看到只有在数据到来的时候才会触发开窗的操作,因此再eventtime的使用时,第一条事件的事件时间和开的窗口的起始时间有一定关系
这里可以看到只有在数据到来的时候才会触发开窗的操作,因此再eventtime的使用时,第一条事件的事件时间和开的窗口的起始时间有一定关系
 上面这个窗口起始时间的计算方式可以看做是timestamp(element中提取的时间戳)对时间窗口取的整数,因为offset默认是0,后面是一个取余的操作,
因此最终的结果就是把余下来的剪掉了,对于上述默认的时间窗口, 我们可以通过offset来进行调整,比如:原本定195
上面这个窗口起始时间的计算方式可以看做是timestamp(element中提取的时间戳)对时间窗口取的整数,因为offset默认是0,后面是一个取余的操作,
因此最终的结果就是把余下来的剪掉了,对于上述默认的时间窗口, 我们可以通过offset来进行调整,比如:原本定195210的,我们可以将offset设置为5,这样就成了200215了。
处理流程:
1、开桶
2、落数据
3、关桶触发计算并再次开启一个新的桶
 在使用了watermark之后还有迟到的数据就可以结合window的allowlateness以及sideoutput来保障数据一定会被处理了。watermark是一种调慢processingtime的机制。
watermark指代的含义是在watermark之前的数据都到齐了(实际也是允许迟到的,可以将watermark设置的更久一点),这就可以将某一个时刻的桶关闭并触发计算了。在实际的生产实践中,
watermark的选择,要看某一个窗口最大的时间戳和延迟的时间戳差值的最大值(这个是应用到分区内的一种规则,也就是说同一个operator实例化出来的subtask可能会由于不同分区接收到
的数据其桶的闭合时机不一致),对于超出了watermark的数据可以使用allowlateness来继续处理,不过每来一条迟到数据就会再触发一次计算,这样会频繁输出临时的中间结果,生产环境不建议使用。
allowlateness(1min)的语义也是watermark到达了一分钟之后才关闭,并不是processingtime到达了某一个时间才关闭。待验证allowlateness的语义
在使用了watermark之后还有迟到的数据就可以结合window的allowlateness以及sideoutput来保障数据一定会被处理了。watermark是一种调慢processingtime的机制。
watermark指代的含义是在watermark之前的数据都到齐了(实际也是允许迟到的,可以将watermark设置的更久一点),这就可以将某一个时刻的桶关闭并触发计算了。在实际的生产实践中,
watermark的选择,要看某一个窗口最大的时间戳和延迟的时间戳差值的最大值(这个是应用到分区内的一种规则,也就是说同一个operator实例化出来的subtask可能会由于不同分区接收到
的数据其桶的闭合时机不一致),对于超出了watermark的数据可以使用allowlateness来继续处理,不过每来一条迟到数据就会再触发一次计算,这样会频繁输出临时的中间结果,生产环境不建议使用。
allowlateness(1min)的语义也是watermark到达了一分钟之后才关闭,并不是processingtime到达了某一个时间才关闭。待验证allowlateness的语义
watermark = max(eventtime - 允许延迟的时间)这个应该是在单个分区内,分区间的话应该是选择min(P(watermark)),如下图所示:
 上图中只有在task的watermark被更新之后才会向下游广播watermark数据。
partition watermark是上游传过来的最小的watermark,watermark是跟随着事件来到下游的subtask的,并不是通过广播的方式进行传输的,
比如forward、rescale、shuffle,因此下游的多个subtask的watermark只有对应分区收到了新的数据,才有可能会更新该子任务的watermark。
(watermark是伴随着事件的流动而流动的,并不会广播,因此在并行度发生变化的时候如果只是发送了一条数据很可能触发不了窗口的关闭)
上图中只有在task的watermark被更新之后才会向下游广播watermark数据。
partition watermark是上游传过来的最小的watermark,watermark是跟随着事件来到下游的subtask的,并不是通过广播的方式进行传输的,
比如forward、rescale、shuffle,因此下游的多个subtask的watermark只有对应分区收到了新的数据,才有可能会更新该子任务的watermark。
(watermark是伴随着事件的流动而流动的,并不会广播,因此在并行度发生变化的时候如果只是发送了一条数据很可能触发不了窗口的关闭)
datastream代码中设置watermark的方式:assigntimestampandwatermark,准确的说这个方法应该叫做extracteventtimestampAndAssignwatermark, 也就是说这个方法会先提取事件时间,然后生成watermark,因此watermark在越靠近source的时候分配就越好。
watermark的生成
watermark生成的接口有两类:perodic和puntatue:分别是代表了周期性定期生成和来了数据之后马上判断要不要生成, 其中周期性生成watermark的方式对于下游的算子压力是比较小的,因此,建议在生产环境中使用。
- 周期性:数据稠密的时候,可以使用这种方式确保watermark的推进
- 间断性:数据稀疏的时候可以保障不会生成过多的watermark

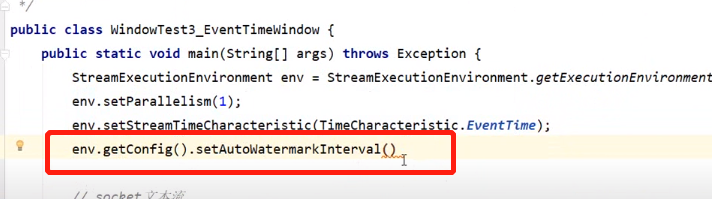 如上默认情况下我们使用的是周期性生成watermark,并且其生成的周期是200ms,不过可以在env中获取这个配置信息并重新设置watermark生成的时间间隔。
如上默认情况下我们使用的是周期性生成watermark,并且其生成的周期是200ms,不过可以在env中获取这个配置信息并重新设置watermark生成的时间间隔。

 如上默认情况下我们使用的是周期性生成watermark,并且其生成的周期是200ms,不过可以在env中获取这个配置信息并重新设置watermark生成的时间间隔。
如上默认情况下我们使用的是周期性生成watermark,并且其生成的周期是200ms,不过可以在env中获取这个配置信息并重新设置watermark生成的时间间隔。这里强调一下:先设置watermark再开窗!先设置watermark再开窗!先设置watermark再开窗!
状态
flink的状态是和算子关联起来的,和特定的子任务绑定在一起,用于保存临时的计算结果,如下图所示:
 按照state的托管状态来说,可以分为manage state(托管到flink的状态)和raw state(需要自己实现状态的管理),
而manage state按照state托管的数据流来分,可以分成
按照state的托管状态来说,可以分为manage state(托管到flink的状态)和raw state(需要自己实现状态的管理),
而manage state按照state托管的数据流来分,可以分成
- manage state:
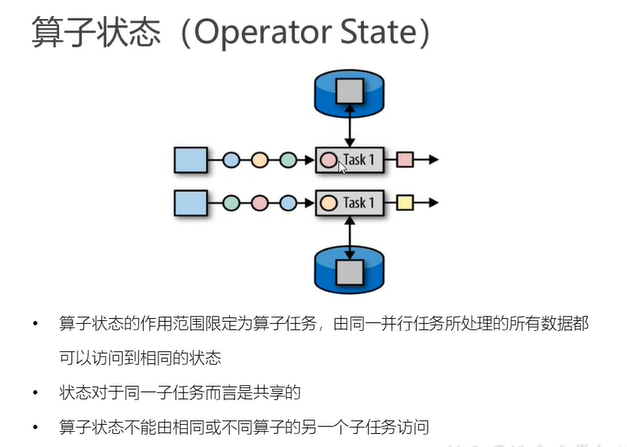
- operator state:针对operator来说只有一个状态(是分区级别的状态),subtask级别共享的状态信息,同一个task不同的subtask是无法做到共享的,
不同operator就更不用说了,所有需要网络传输的状态都是无法共享的,可以认为状态数据是存在于本地内存的数据。对于operator state来说不管前面是否做过keyBy之类的操作,
对于同一个并行的子任务来说都是同一个状态,是不区分key的。当然前面不一定做过可以KeyBy。
 operator state底层状态的定义存在以下几种数据结构:
operator state底层状态的定义存在以下几种数据结构:- liststate:列表状态,在任务的并行度调整的时候会将liststate进行拆分,因此这里的state是一个liststate,而不是valuestate,主要是方便任务的并行度调整之后的状态的划分。
- union liststate:联合列表状态:和liststate的区别在于,当任务从保存点或者检查点恢复的时候,原来算子的不同子任务的状态会做一次合并发送到新的任务。
- broadcast state:广播状态,同一个算子的各个子任务的状态数据是一致的。
- operator state:针对operator来说只有一个状态(是分区级别的状态),subtask级别共享的状态信息,同一个task不同的subtask是无法做到共享的,
不同operator就更不用说了,所有需要网络传输的状态都是无法共享的,可以认为状态数据是存在于本地内存的数据。对于operator state来说不管前面是否做过keyBy之类的操作,
对于同一个并行的子任务来说都是同一个状态,是不区分key的。当然前面不一定做过可以KeyBy。
 operator state底层状态的定义存在以下几种数据结构:
operator state底层状态的定义存在以下几种数据结构:上面可以看到operator state没有valuestate,只有list、unionlist以及broadcast state,原因是operator在并行度调整的时候可能会出现状态的拆分或者合并。 union list state在任务重启的时候会把state数据进行合并,然后广播给每一个子任务,由子任务自行决策要使用哪一个状态信息。 算子状态从使用上来说就和本地变量是一致的。算子状态有使用的场景(source、sink中会使用),不过更多的是和key相关的状态。算子状态需要实现checkpoint的接口, 不需要使用richfunction来定义对应的状态,其本身就是transform里面的一个本地变量。
另外对于state来说究竟是先声明还是在open方法打开,其主要关注点在于是否可以获取到context信息,如果可以获取到context信息,则必定可以实现定义:
 这里operator定义一个本地变量是一种最简单的状态,不过针对这个本地变量在任务checkpoint或者savepoint的时候,需要能够将其保存和恢复,
因此持有状态的算子还必须实现ListCheckpoint的接口(接口是一个泛型,其保存的类型和本地变量的类型要一致),在实现保存点状态恢复的时候需要注意其参数是一个List,
原因是因为并行度可能会发生调整,因此存在一个子任务接收了多个原来子任务的状态数据。具体代码如下:
这里operator定义一个本地变量是一种最简单的状态,不过针对这个本地变量在任务checkpoint或者savepoint的时候,需要能够将其保存和恢复,
因此持有状态的算子还必须实现ListCheckpoint的接口(接口是一个泛型,其保存的类型和本地变量的类型要一致),在实现保存点状态恢复的时候需要注意其参数是一个List,
原因是因为并行度可能会发生调整,因此存在一个子任务接收了多个原来子任务的状态数据。具体代码如下:

keyed state:对于keyedstate,每一个key都对应了一个state,每一个subtask会分配多个key,因此每一个subtask会存在多个key的state,并且对于keyedstate状态数据的访问, 不同的key彼此之间是无法互访state的(比operator约束更严格,operator只要求subtask之间无法互访,这里要求同一个subtask下的不同的key也无法互访,对应的数据结构如下:
- valuestate:之所以valuestate有效是因为不同的key对应了不同的valuestate,因此在任务并行度调整的时候天然的具备rehash的能力。
- liststate:
- mapstate:
- reducing state、aggregatingstate:这两种数据结构指代的是在数据到来的时候对原有的state进行一个聚合操作。
 键控状态区别于operatorstate,keystate需要获取运行的上下文环境,这是因为来了一个数据之后需要根据这个key获取对应的状态(因为同一个subtask存储了多个key的状态信息),
也就是说getRuntimeContext实现的是不同key的状态的隔离,也正因为getRuntimeContext的调用,因此operator必须是RichFunction,这样才可以调用到这个方法。
键控状态区别于operatorstate,keystate需要获取运行的上下文环境,这是因为来了一个数据之后需要根据这个key获取对应的状态(因为同一个subtask存储了多个key的状态信息),
也就是说getRuntimeContext实现的是不同key的状态的隔离,也正因为getRuntimeContext的调用,因此operator必须是RichFunction,这样才可以调用到这个方法。
 键控状态区别于operatorstate,keystate需要获取运行的上下文环境,这是因为来了一个数据之后需要根据这个key获取对应的状态(因为同一个subtask存储了多个key的状态信息),
也就是说getRuntimeContext实现的是不同key的状态的隔离,也正因为getRuntimeContext的调用,因此operator必须是RichFunction,这样才可以调用到这个方法。
键控状态区别于operatorstate,keystate需要获取运行的上下文环境,这是因为来了一个数据之后需要根据这个key获取对应的状态(因为同一个subtask存储了多个key的状态信息),
也就是说getRuntimeContext实现的是不同key的状态的隔离,也正因为getRuntimeContext的调用,因此operator必须是RichFunction,这样才可以调用到这个方法。valuestate的使用说明:
声明和定义需要分开,原因是如果声明和定义放到一起的话会存在一个问题,因为声明的时候是对象的一个属性,所以会直接在jobmanager里面完成对象的创建,
而getRuntimeContext则是operator按照并行度实例化成subtask之后分发到对应的slot上才具备的方法,因此生命和定义要分开,声明在类中直接定义一个属性,
而定义需要在open方法中完成属性的实例化。状态变量赋初始值的情况可以在定义的时候指定,也可以在对应的获取state的时候通过判断是否为null来给赋初值,其使用代码示例如下:
 reducingState要求传入三个参数,其中中间的参数是一个reduceFunction,该reduceFunction会在下面诸如map中更新这个值的时候被使用。代码如下:
reducingState要求传入三个参数,其中中间的参数是一个reduceFunction,该reduceFunction会在下面诸如map中更新这个值的时候被使用。代码如下:

除了追加更新state之外,还有一个方法clear可以用来清空内存中的状态信息
上述两种类型的state都需要有对应的状态后端支持,这里的状态后端就是state backends,常见的状态后端有MemoryStateBackend、 HDFSStateBackend、RocksDBstateBackend。提到state就不得不提另外一个概念Checkpoint,Checkpoint是将上述的状态 数据持久话起来,对于MemoryStateBackend和HdfsStateBackend来说其状态数据是存放到Taskmanager的堆内存中,在做checkpoint的时候 MemeryStateBackend是把checkPoint的数据存放到jobmanager中,我们知道jobmanager的内存大小一般是有限制的,因此MemoryStateBackend并不 适用于生产环境中执行的作业,因为一旦作业挂掉了状态就会丢失,二对于HdfsStateBackend在做checkPoint的时候会将对应的数据存放到hdfs上进行持久化,因此 状态可以保存很久,对于RocksDBStateBackend来说,作业在运行的时候状态数据并不是保存在TaskManager的堆内存中的,二十保存在Managed memory中的对外内存的, 在做checkPoint的时候则是将持久化的状态数据写入到HDFS中,不过使用MemoryStateBackend有一个需要注意的问题,那就是其只支持Keyedstate,并不支持 operatorstate。
状态后端
1、负责维护和更新状态数据
2、将检查点状态写入远程存储,确保数据的可靠性
 如前所述,状态后端存在以下几种选择:
如前所述,状态后端存在以下几种选择:
 memorystatebackend和fsstatebackend,其状态数据都是存放到本地的taskmanager的内存里面的,而rocksdb的状态数据是存储在rocksdb里面的
(本地内存作为缓存,rocksdb基于内存开辟了一个空间,超出rocksdb的大小限制的时候就会落盘),以上是状态数据的保存;而对于checkpoint的保存的话,
memorystatebackedn是将数据存放到jobmanager中,在taskmanager有故障发生重启的时候,可以用来恢复作业的状态,不过一旦jobmanager挂了就无解了,
而fsstatebackend和rocksdb statebackend来说,checkpoint的数据则是存放在hdfs上的,这一点和状态数据的存放是不一样的。
memorystatebackend和fsstatebackend,其状态数据都是存放到本地的taskmanager的内存里面的,而rocksdb的状态数据是存储在rocksdb里面的
(本地内存作为缓存,rocksdb基于内存开辟了一个空间,超出rocksdb的大小限制的时候就会落盘),以上是状态数据的保存;而对于checkpoint的保存的话,
memorystatebackedn是将数据存放到jobmanager中,在taskmanager有故障发生重启的时候,可以用来恢复作业的状态,不过一旦jobmanager挂了就无解了,
而fsstatebackend和rocksdb statebackend来说,checkpoint的数据则是存放在hdfs上的,这一点和状态数据的存放是不一样的。
状态后端的使用如下:
 上述是设置状态后端的时候代码里面的设置。。。(看着是departched方法,不过实际上并没有其他方法可以调用,因此这里还是使用这种方式),
上述设置状态后端的时候无论是hdfs还是rocksdb,都需要指定一个路径,其中rocksdb也是指定一个hdfs的路径,并且rocksdb具备是否开启增量快照的机制
上述是设置状态后端的时候代码里面的设置。。。(看着是departched方法,不过实际上并没有其他方法可以调用,因此这里还是使用这种方式),
上述设置状态后端的时候无论是hdfs还是rocksdb,都需要指定一个路径,其中rocksdb也是指定一个hdfs的路径,并且rocksdb具备是否开启增量快照的机制
checkpoint & savepoint
checkpoint又叫做检查点,其就包含两个操作:
- 存
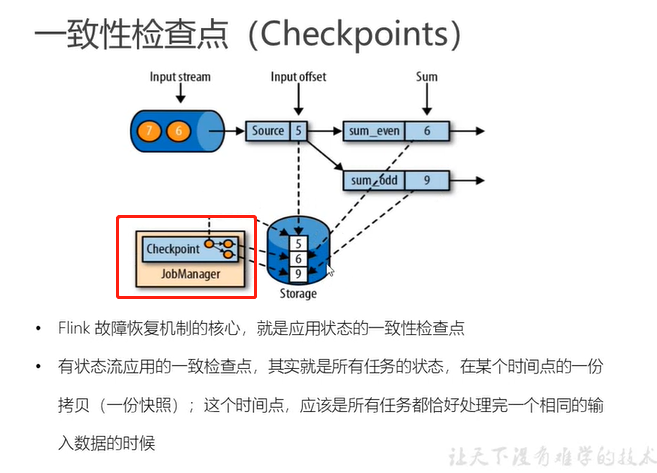 这里的同一个时间点的一份快照准确的说是同一个数据的快照,也就是说所有的下游任务都处理完了同一个数据,那么这样就可以确保全局的状态的一致性
这里的同一个时间点的一份快照准确的说是同一个数据的快照,也就是说所有的下游任务都处理完了同一个数据,那么这样就可以确保全局的状态的一致性 - 恢复
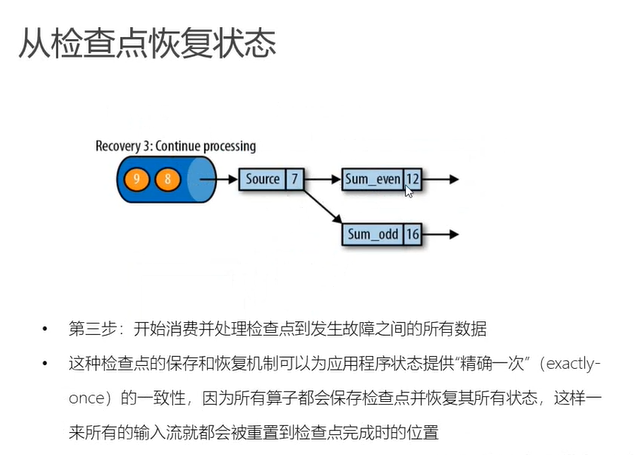
- 重启任务,初始状态为null
- jobmanager从状态后端中读取状态数据并重新将各个subtask的状态恢复出来
 这里的同一个时间点的一份快照准确的说是同一个数据的快照,也就是说所有的下游任务都处理完了同一个数据,那么这样就可以确保全局的状态的一致性
这里的同一个时间点的一份快照准确的说是同一个数据的快照,也就是说所有的下游任务都处理完了同一个数据,那么这样就可以确保全局的状态的一致性
检查点基本思路: 1、所有算子的所有任务都停下来进行打快照操作,这种方式带来的问题是任务的阻塞 2、所有的算子各自打各自的快照,这样只会阻塞打快照的算子的操作 3、针对打快照的子任务,其状态数据进行内存的拷贝,拷贝的状态数据进行快照,原状态数据可以写入checkpoint中
上面每一个子任务都有一个状态信息保存下来,保存到指定的目录中,按理说这种写数据的方式,其目录结构应该是和job的execution graph一致,这样可以方便的重构任务(猜测!!)。
flink的checkpoint类似于perodic watermark,其本质上是在正常的数据流里面插入一下checkpoint barrier的事件,算子在接收到一个非正常的事件的时候会根据事件的类型做相应的操作
如下图所示:
 watermark是通过assigntimestampandwatermark将watermark插入到调用了这个方法的operator对应的,正常的数据流里面的。barrier则是在source里面产生的,
并且是由jobmanager负责协调产生的。上图中的2代表了chekpoint的id,jobmanager将chekpoint barrier(包含了checkpoint id信息的一条event)
插入到正常的数据流里面,在将checkpoint插入到source对应的数据流里面的时候后并不会影响后续的算子
watermark是通过assigntimestampandwatermark将watermark插入到调用了这个方法的operator对应的,正常的数据流里面的。barrier则是在source里面产生的,
并且是由jobmanager负责协调产生的。上图中的2代表了chekpoint的id,jobmanager将chekpoint barrier(包含了checkpoint id信息的一条event)
插入到正常的数据流里面,在将checkpoint插入到source对应的数据流里面的时候后并不会影响后续的算子
 jobmanager 发出checkpoint barrier之后,source 算子的subtask将对应的状态数据保存到状态后端,之后再向jobmanager发出确认信息告诉jobmanager自己已经完成了checkpoint。
checkpoint barrier这种特殊数据会广播到下游的所有的算子,并不是随着数据向下游传输。
jobmanager 发出checkpoint barrier之后,source 算子的subtask将对应的状态数据保存到状态后端,之后再向jobmanager发出确认信息告诉jobmanager自己已经完成了checkpoint。
checkpoint barrier这种特殊数据会广播到下游的所有的算子,并不是随着数据向下游传输。
 如上,因为checkpoint barrier是通过广播的方式发送到下游的,因此下游的任务会等待上游所有分区的barrier全都到达了才会进行checkpoint,
这个时候当前算子的subtask因为要等待所有的barrier,因此这个subtask会暂停处理已到达barrier的上游的数据。
如上,因为checkpoint barrier是通过广播的方式发送到下游的,因此下游的任务会等待上游所有分区的barrier全都到达了才会进行checkpoint,
这个时候当前算子的subtask因为要等待所有的barrier,因此这个subtask会暂停处理已到达barrier的上游的数据。
 在下游的算子做完checkpoint之后,会优先处理之前缓存的数据。
1
所有的任务都完成之后,jobmanager就会收到对应的信息,这样这个checkpoint就完成了保存,后续的任务就可以从这个checkpoint中再次恢复出来。
在下游的算子做完checkpoint之后,会优先处理之前缓存的数据。
1
所有的任务都完成之后,jobmanager就会收到对应的信息,这样这个checkpoint就完成了保存,后续的任务就可以从这个checkpoint中再次恢复出来。
flink中保存点(从原理上来说保存点和检查点是同一种实现逻辑)
 保存点在整个作业的DAG不发生更改的情况下,可以创建保存点,然后微调代码,最后从之前创建的保存点恢复作业。
保存点在整个作业的DAG不发生更改的情况下,可以创建保存点,然后微调代码,最后从之前创建的保存点恢复作业。
接下来我们看一下checkpoint在代码中的一些关键特性:
 这里的高级选项:pausebetweencheckpoints优先级高于checkpointinterval,并且高于maxcurrentcheckpoint选项,因为pause就意味着同一个时刻只可以有一个checkpoint执行了
这里的高级选项:pausebetweencheckpoints优先级高于checkpointinterval,并且高于maxcurrentcheckpoint选项,因为pause就意味着同一个时刻只可以有一个checkpoint执行了
 上面这个配置项指代的含义是如果一个subtask的checkpoint出现了问题之后,是否重启当前任务,为0代表了只要checkpoint失败了,也认为当前任务已经失败了。
既然失败了就有对应的重启策略,
上面这个配置项指代的含义是如果一个subtask的checkpoint出现了问题之后,是否重启当前任务,为0代表了只要checkpoint失败了,也认为当前任务已经失败了。
既然失败了就有对应的重启策略,
 重启配置中失败率重启是存在了两个判断条件:中间的参数代表了允许重启的最大时间段,超过这个时间段还没有完成重启的话,就认为任务失败了,第一个只带了10分钟内超过了三次也算失败,
因此前两个参数只要有一个满足就标志着重启失败,最后一个参数代表了在没有达到重启失败之前,任务重启的最小时间间隔,最低要保障每次重启之间要有1分钟的时间空闲,
不要上一次重启失败之后立马再次重启。
重启配置中失败率重启是存在了两个判断条件:中间的参数代表了允许重启的最大时间段,超过这个时间段还没有完成重启的话,就认为任务失败了,第一个只带了10分钟内超过了三次也算失败,
因此前两个参数只要有一个满足就标志着重启失败,最后一个参数代表了在没有达到重启失败之前,任务重启的最小时间间隔,最低要保障每次重启之间要有1分钟的时间空闲,
不要上一次重启失败之后立马再次重启。
一致性语义
flink只能够保障flink组件内部的状态(就是state)一致性,其是通过上面所说的checkpoint来保障的,但是其仅能保障flink内部的一致性,如果对接外部的数据源的话, 就很难保障一致性的语义了,以kafka为例,如果要实现exactly once的消费语义:
- source端数据的读入需要通过offset保障可以重复消费
- flink内部的状态数据可以保障数据只消费一次
- sink端exactly once需要通过事务、幂等二者之一来实现。
- 幂等:其中,sink端幂等写入会存在历史数据的回放效应,如果连续监测的话,就会出现数据的跳变,从而形成误告。因此幂等写入存在以下问题:
- 对外部系统有要求
- 外部系统的状态存在跳变的情况。
- 事务:flink对于事务的写入存在两种语义可以实现:

- 两阶段提交
其中两阶段提交依赖写入系统的支持,当前在kafka中有应用,其流程如下

- WAL
 flink中提供了这种sink类可以用来实现在checkpoint完成之后写入到外部系统,可以实现基于WAL的事务性sink,不过这种存在问题,那就是批处理模型
flink中提供了这种sink类可以用来实现在checkpoint完成之后写入到外部系统,可以实现基于WAL的事务性sink,不过这种存在问题,那就是批处理模型
- WAL
- 两阶段提交
其中两阶段提交依赖写入系统的支持,当前在kafka中有应用,其流程如下
- 幂等:其中,sink端幂等写入会存在历史数据的回放效应,如果连续监测的话,就会出现数据的跳变,从而形成误告。因此幂等写入存在以下问题:
 flink中提供了这种sink类可以用来实现在checkpoint完成之后写入到外部系统,可以实现基于WAL的事务性sink,不过这种存在问题,那就是批处理模型
flink中提供了这种sink类可以用来实现在checkpoint完成之后写入到外部系统,可以实现基于WAL的事务性sink,不过这种存在问题,那就是批处理模型{kind=link}
小结
有关于flink的总结先到此为止,对应代码测试见github:github demo,另外学习flink的过程中大量 参考了尚硅谷的flink教程