分布式共识算法
概述
说起分布式算法,业内出名的有paxos、raft,不过大部分介绍资料一般都仅限于介绍具体的实现,很少有针对其合理性以及为什么这样做进行解释。什么任期、提案,包括什么提议者、接收者、学习者,甚至于leader,这么一堆复杂的概念绕在一起,一会就把人给绕晕了,我曾经尝试看过很多资料,大部分都没有针对这种算法的合理性做出解释,最近在重新思考分布式一致性的时候忽然有所感悟,顺便上网搜了一下相关的资料,算是勉强的把这个问题给理顺了。
详解
分布式共识vs分布式事务
在介绍分布式共识算法之前,我认为有必要说一下分布式共识算法和分布式事务之间的关系,私以为二者是不存在任何关系的。首先从解决的问题来看,分布式共识算法是为了解决分布式系统的高可用问题,分布式事务则是为了解决分布式系统之间数据的一致性的问题,这两个分布式系统是有所不同的,对于分布式共识中的分布式可以认为是每一个节点的服务是相同的服务;而对于分布式事务之中的分布式,每一个节点的服务是不相同的,分布式事务要做的工作是让这些不同的服务看起来像一个整体一样:针对客户端的某个操作,不同的服务要么同时成功,要么同时失败。总结一下分布式共识是A1、A2、A3、A4、A5这样子的关系,而分布式事务是A、B、C、D的关系。
分布式共识解决的问题
分布式共识算法解决的是系统的高可用问题。对于早期的单节点服务,如果因为电脑死机或者网络故障,会导致单节点服务变得不可用,为了保障服务的可用性,就引入了副本的机制,常见的有主-从、主-备,当主节点挂了之后从节点或者备件点马上就补上去,这样整个系统的可用性就可以大大的提高,但是因为引入了副本节点就会带来一致性的问题。我们来看一下常见的主从同步的方式以及存在的一些问题:
特别强调:已经给客户端确认的消息就必定是确认的,没有给客户端确认的消息存在状态的不确定性,需要客户端通过重试来确认最终的状态,因此我们再分析问题的时候只需要针对已经返回给客户端ok的系统异常进行分析,这才是分布式共识的得救之道。
主从异步复制
 如上图所示,客户端发起请求set x=5,master接受请求之后,立即返回client告知请求成功,同时将set x=5发往slave节点,由于master和slave之间网络的不可靠,导致消息丢失,但是cleint和master的网络并没有问题,client收到成功的响应,此时master由于某种原因下线了,而slave1、slave2并没有成功的收到客户的请求,因此就会出现认知的问题:client认为已经系统已经成功的接受了请求,然而master下线之后,如果选择一个slave提升为master,由于对应的slave并没有收到响应的请求,因此就出现了数据的丢失。上面这种方式在系统内部是可靠的情况的时候,是能够提升整个系统的可用性的,但是当系统内部环境不可靠的时候,会降低整个系统的可用性。
如上图所示,客户端发起请求set x=5,master接受请求之后,立即返回client告知请求成功,同时将set x=5发往slave节点,由于master和slave之间网络的不可靠,导致消息丢失,但是cleint和master的网络并没有问题,client收到成功的响应,此时master由于某种原因下线了,而slave1、slave2并没有成功的收到客户的请求,因此就会出现认知的问题:client认为已经系统已经成功的接受了请求,然而master下线之后,如果选择一个slave提升为master,由于对应的slave并没有收到响应的请求,因此就出现了数据的丢失。上面这种方式在系统内部是可靠的情况的时候,是能够提升整个系统的可用性的,但是当系统内部环境不可靠的时候,会降低整个系统的可用性。
主从同步复制
 如上图所示,主从同步复制的过程是client发起set x = 5的请求,master接收到之后,第一时间将该指令发往slave1、slave2,slave1、slave2在成功接收到请求之后,将反馈给master告知其已经收到相关客户的请求,之后master将告知client说明请求已经处理完成。主从同步相较于异步的好处在于,client收到了来自master成功的消息,那么系统中所有节点必然是都处理完了,也就是说整个系统是一致的状态,但是带来的弊端也是显而易见的,那就是如果slave1挂掉了,那么master将迟迟收不到来自slave1的确认消息,整个系统就处于不可用的状态。
如上图所示,主从同步复制的过程是client发起set x = 5的请求,master接收到之后,第一时间将该指令发往slave1、slave2,slave1、slave2在成功接收到请求之后,将反馈给master告知其已经收到相关客户的请求,之后master将告知client说明请求已经处理完成。主从同步相较于异步的好处在于,client收到了来自master成功的消息,那么系统中所有节点必然是都处理完了,也就是说整个系统是一致的状态,但是带来的弊端也是显而易见的,那就是如果slave1挂掉了,那么master将迟迟收不到来自slave1的确认消息,整个系统就处于不可用的状态。
半同步复制
 如上图所示,半同步复制是只要master收到了来自一半的slave节点的确认就返回给客户端ok的响应。看似提高了系统的可用性,但是这里任然存在一个问题:client第一次发送set x = 5,master将该请求发给了slave1,然后client第二次发送了set y = 6,master将该请求发给了slave2,此时假定master挂了,需要从slave1和slave2中选择一个节点作为master,那么选择哪一个作为master就没有办法判断了。上述的两个请求必然丢失一个
如上图所示,半同步复制是只要master收到了来自一半的slave节点的确认就返回给客户端ok的响应。看似提高了系统的可用性,但是这里任然存在一个问题:client第一次发送set x = 5,master将该请求发给了slave1,然后client第二次发送了set y = 6,master将该请求发给了slave2,此时假定master挂了,需要从slave1和slave2中选择一个节点作为master,那么选择哪一个作为master就没有办法判断了。上述的两个请求必然丢失一个
多数派读写(无主从)
针对此种情况将不再存在主从,集群中的节点是平等的。 针对上面半同步复制存在的问题,我们可以采取的策略是半数写、半数读,这样client将set x = 5发给集群中半数的节点并获得响应之后,假定master节点(此时并不是主节点了,我们可以将其假想为节点的名字)之后,master将请求发给了slave1,之后客户端收到了ok的响应;接下来client发送set y = 6发给了slave2,slave2将该请求发给了master并给客户端发送了ok的消息,此时如果其中一个节点master挂掉了,我们想要读取x或者y的值需要将两个节点的查询结果进行合并就可以了。
我们通过多数派的写、多数派的读最终可以得到正确的结果,即便系统中有半数以下的节点都挂掉了,已经返回给客户端确认的消息依然是能够在系统中被正常读取,但是这里却存在一个问题,那就是数据的更新。假定client发给master set x = 5,slave1和master同时接受了指令,接下来client 继续发送set x = 6,slave2和master也同时接受了指令,两个请求客户端都收到了ok的响应。接下来master挂掉了,client需要读取x的值,这个时候读取到slave1返回了5,slave2返回了6,那么x值到底为哪个就无法确认了。
针对上述问题一个很好的解决方案就是设置时间戳,设置了时间戳之后,slave1返回的是5(t1),slave2返回的是6(t2),这样我们就认为6才是有效的值,but这里依然存在一个问题:假如client在发送请求的时候slave2率先接到了这个请求,还没有来得及给master发送,并且slave2和slave1之间存在网络问题,那么此时如果master挂掉了,client在查询x值的时候怎么知道6(t2)数据的有效性?也就是说无法确认6(t2)是否已经被多数节点认可了,因此6就成了一个不可确认的状态。
因此针对数据的更新时间戳并没有办法完美解决的答案。paxos可以认为是多数派读写的一种升级,通过两次多数派读写完美的达成了一致。
多数派读写到paxos的演化
假设我们存在一个分布式的存储系统(每个分布式实例可以以map为例),针对这个存储系统存在以下三种操作:get(查询)、set(设置)、inc(增加),在此基础上我们需要借助多数派读写实现一个强一致性的系统。set和inc的过程如下:
 我们先来看一下inc的过程,inc会先获取节点中的值,然后对其做自增操作,继而写入存储系统,如果有多个客户端并发的去inc对应的值,那么就出现了数据丢失的问题:系统中x的初始值假定为1,c1取出来数据并在存储系统之外进行自增操作,在未写入存储系统之前,c2也发起inc的操作,并取出x的值(此时仍然未1)并在存储系统之外自增,这时候c1和c2自增之后的结果都是2,但是这里显然存在更新丢失的问题,也就是说x在c1和c2完成自增之后应该为3。为了解决这个问题我们可以将inc分解为以下两个过程:
我们先来看一下inc的过程,inc会先获取节点中的值,然后对其做自增操作,继而写入存储系统,如果有多个客户端并发的去inc对应的值,那么就出现了数据丢失的问题:系统中x的初始值假定为1,c1取出来数据并在存储系统之外进行自增操作,在未写入存储系统之前,c2也发起inc的操作,并取出x的值(此时仍然未1)并在存储系统之外自增,这时候c1和c2自增之后的结果都是2,但是这里显然存在更新丢失的问题,也就是说x在c1和c2完成自增之后应该为3。为了解决这个问题我们可以将inc分解为以下两个过程:
- 询问:通过多数派读询问是否有其他节点要更新
- 执行操作:根据询问的结果来确定是否执行下一步操作,如果发现有其他节点要更新数据,那么就直接结束或者发起下一轮的询问,如果发现没有其他节点要执行操作,那么就通过多数派写来更新数据
上述过程显而易见的依然存在漏洞:那就是可能存在多个写前读(也可以认为是多数派读)来确认是否执行下一步的操作,这样依然存在更新丢失的情况。解决这个问题的关键在于改造节点,让节点记住哪一个client最后发起的写前读操作(也就是第一阶段的读操作),节点只允许最新的写前读操作执行真正的写操作。通过这种方式就完美的避开了inc丢失的问题。set操作其实也可以认为是inc的操作,只是我们第一步拿出来的值是null
上述过程分别是通过多数派读和多数派写两个过程完美的解决了分布式一致性的问题,这也是paxos的核心所在。
paxos
paxos中存在以下几种角色:
- proposer:提议者,我们可以将其认为是客户端
- Acceptor:我们可以理解为节点的存储服务
- Quorum:集群中半数以上的acceptor节点
- Round:用来标记一次paxos算法的实例,包含了两个phase,这两个phase分别是
多数派读和多数派写,这里多数一句acceptor对应的存贮结构应该如下: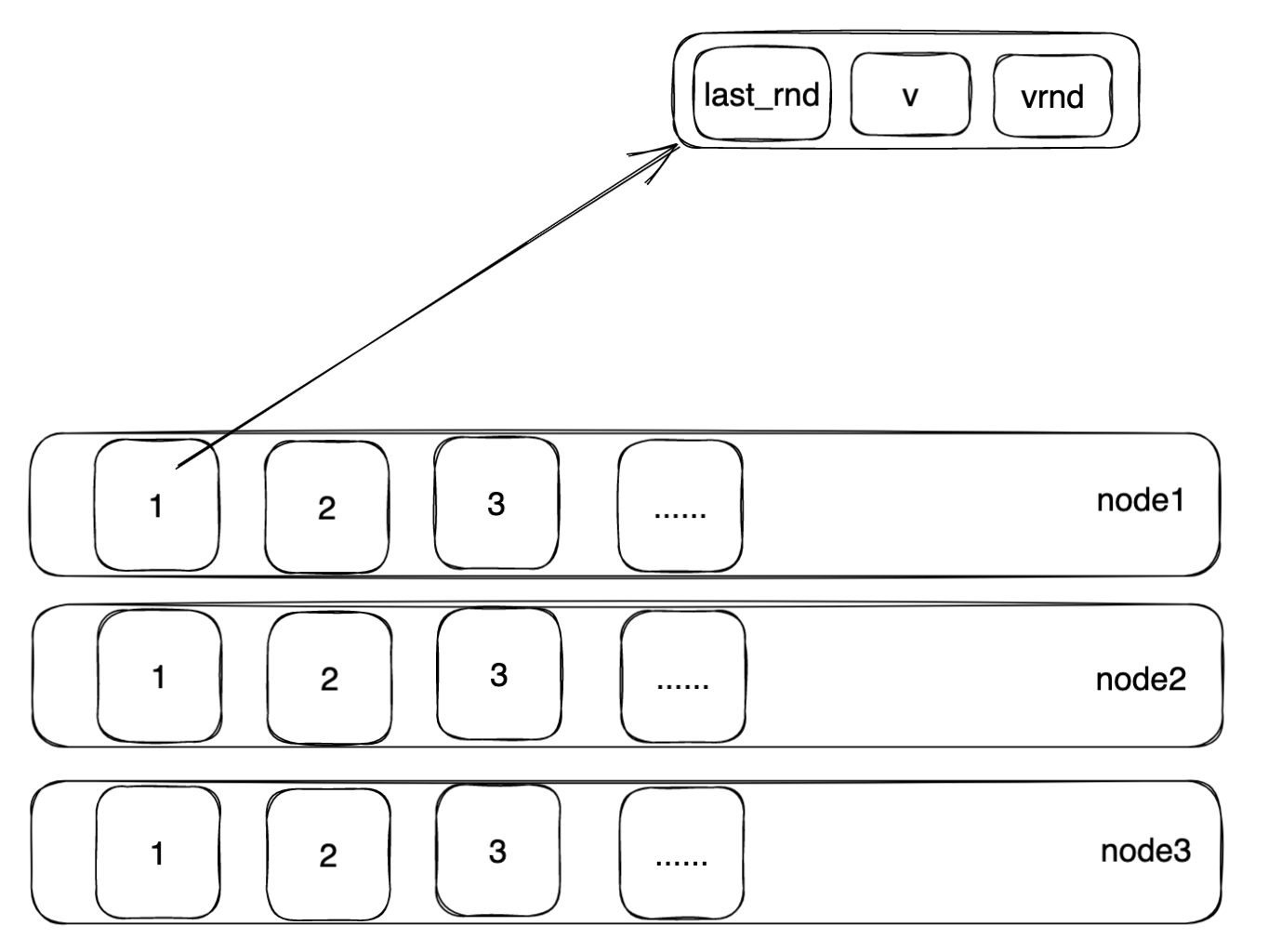 如上图所示,每一个node都有一些列的小格子,节点中的每一个小格子中的数字代表了一个偏移量,我们的每一次paxos算法实例都是针对node中的小格子内容达成的共识,针对上图即是至少存在三次paxos算法实例。那可能有的同学会问,如果client1提交的某一条记录失败了要怎么办?其实我们只需要在下一个paxos算法实例继续提交即可,也就是说我们在1号小格子提交失败的可以继续放到2号小格子继续提交。
如上图所示,每一个node都有一些列的小格子,节点中的每一个小格子中的数字代表了一个偏移量,我们的每一次paxos算法实例都是针对node中的小格子内容达成的共识,针对上图即是至少存在三次paxos算法实例。那可能有的同学会问,如果client1提交的某一条记录失败了要怎么办?其实我们只需要在下一个paxos算法实例继续提交即可,也就是说我们在1号小格子提交失败的可以继续放到2号小格子继续提交。
 如上图所示,每一个node都有一些列的小格子,节点中的每一个小格子中的数字代表了一个偏移量,我们的每一次paxos算法实例都是针对node中的小格子内容达成的共识,针对上图即是至少存在三次paxos算法实例。那可能有的同学会问,如果client1提交的某一条记录失败了要怎么办?其实我们只需要在下一个paxos算法实例继续提交即可,也就是说我们在1号小格子提交失败的可以继续放到2号小格子继续提交。
如上图所示,每一个node都有一些列的小格子,节点中的每一个小格子中的数字代表了一个偏移量,我们的每一次paxos算法实例都是针对node中的小格子内容达成的共识,针对上图即是至少存在三次paxos算法实例。那可能有的同学会问,如果client1提交的某一条记录失败了要怎么办?其实我们只需要在下一个paxos算法实例继续提交即可,也就是说我们在1号小格子提交失败的可以继续放到2号小格子继续提交。针对上图中的每一个小格子我们展开看到存在如下三个值:
- last_rnd:多数读发生的时候最新的多数读rnd,rnd是全局递增并且唯一的
- v:最后写入到节点的值
- vrnd:写入到节点的值对应的rnd
接下来我们针对paxos的过程进行分析,我们首先假定其中的报文格式如下:
1 | request: |
proposer在发起request之后,acceptor会有两种响应:
- 拒绝:说明acceptor中已经记录了高于rnd的请求
- 接收:acceptor保留request请求的rnd作为last_rnd,此时acceptor只会接受带有last_rnd的phase2的请求,或者rnd大于last_rnd的phase的请求。
对于接受的处理比较简单,只需要直接进入第二阶段就行了。但是对于拒绝的请求可能存在以下两种情况: 多数读请求返回的结果没有对应的v和vrnd,那么说明有其他的phase1大于当前Proposer的请求存在了,这个时候可以随机等待一段时间继续发起请求。 多数请求返回了对应的v和vrnd,这时候我们需要返回最大的vrnd对应的v,作为本次提议的值即可,至于Proposer原来提议的值可以等到下一个小格子继续提议。针对返回对应的v及vrnd的情况会存在以下两种情况:
- v、vrnd已经是多数派了,这种情况下我们提交自然没有什么问题
- v、vrnd还是少数派,针对这种情况我们可以将当前Proposer看做是接力的作用。无论是哪种情况都保证了系统的一致性。(已经确认的绝对不会丢失,但是没有确认的有可能会被提交。)
上面proposer的phase1阶段已经完成了,接下来是phase2阶段,这个就比较简单了直接提交proposer当前拥有的值即可,对应的v、vrnd均会被持久化写入。
multi-paxos
区别于paxos的2次多数读、多数写操作,multiple是在多数读阶段一次性提交了多个多数读,多数写仍然是一个一个进行的写,这样做的好处是原来可能需要20次读、写操作,现在只需要11次。
fast-paxos
fast-paxos的过程相对来说比较简单,首先直接进入phase2阶段,如果系统是干净的、并且没有竞争那么直接就成功了,如果系统不干净或者存在多个竞争,那么就会退化为paxos。
fast-paxos存在一个问题,我们假设是2n+1个节点,如果其中的n+1个直接在proposer1的phase2的过程就确认了,但是另外n个几点没有存放的是其他proposer2对应的phase2的值,这个时候直接返回客户端ok的信息,客户端认为proposer1已经确认了,但是此时确认了proposer1的其中的n个节点突然挂了,此时剩下了1个proposer1和n个proposer2,我们无法确认是proposer1被确认了还是proposer2被确认了。这种情况就要扩大多数节点的数量。原来是大于n/2,需要变成大于n/2+(n/2)/2,也就是大于3*n/4个节点正常工作才可以,这里不像是n/2+1个节点,不需要多个1,是因为集群的节点必然是奇数,因此除4必然是会带小数,因此我们只需要向上取整就可以了,因此此时集群最少得有5个节点,并且至少此时至少要有4个节点正常记录才可以。